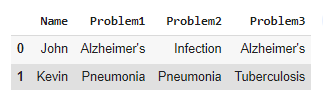
Now to delete or replace the duplicate with empty space:
df['Problem2']=df.apply(lambda x:x["Problem2"] if not(x["Problem2"]==x['Problem1']) else " ",axis=1)
df['Problem3']=df.apply(lambda x:x["Problem3"] if not(x["Problem3"]==x['Problem2'] or x["Problem3"]==x['Problem1']) else " ",axis=1)
df
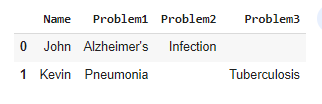
CodePudding user response:
You can try to use the df.duplicated-function for this. This works similar to df.drop_duplicates but returns a boolean series instead of removing the duplicates. You can then index your initial dataframe by this boolean series setting the values to None.