I am attempting to extract links from a website that does not use a href. I have tried multiple iterations of trying to find the tag associated with the url that from what I can gather is between <span> elements.
import requests
from bs4 import BeautifulSoup
url = 'https://www.flavortownusa.com/locations'
page = requests.get(url)
f = open("test12.csv", "w")
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('div', class_ = 'listing-item-inner')
for list in lists:
title = list.find('span', class_ = '$0')
webs = list.find('#text', class_ = 'fa-fa.link')
address = list.find('ul', class_ = 'post-meta')
temp = list.find('span', class_ = 'text')
temp2 = list.find('i', class_ = '(text)')
info = [title, webs, address, temp, temp2]
f.write(str(info))
f.write("\n")
print(info)
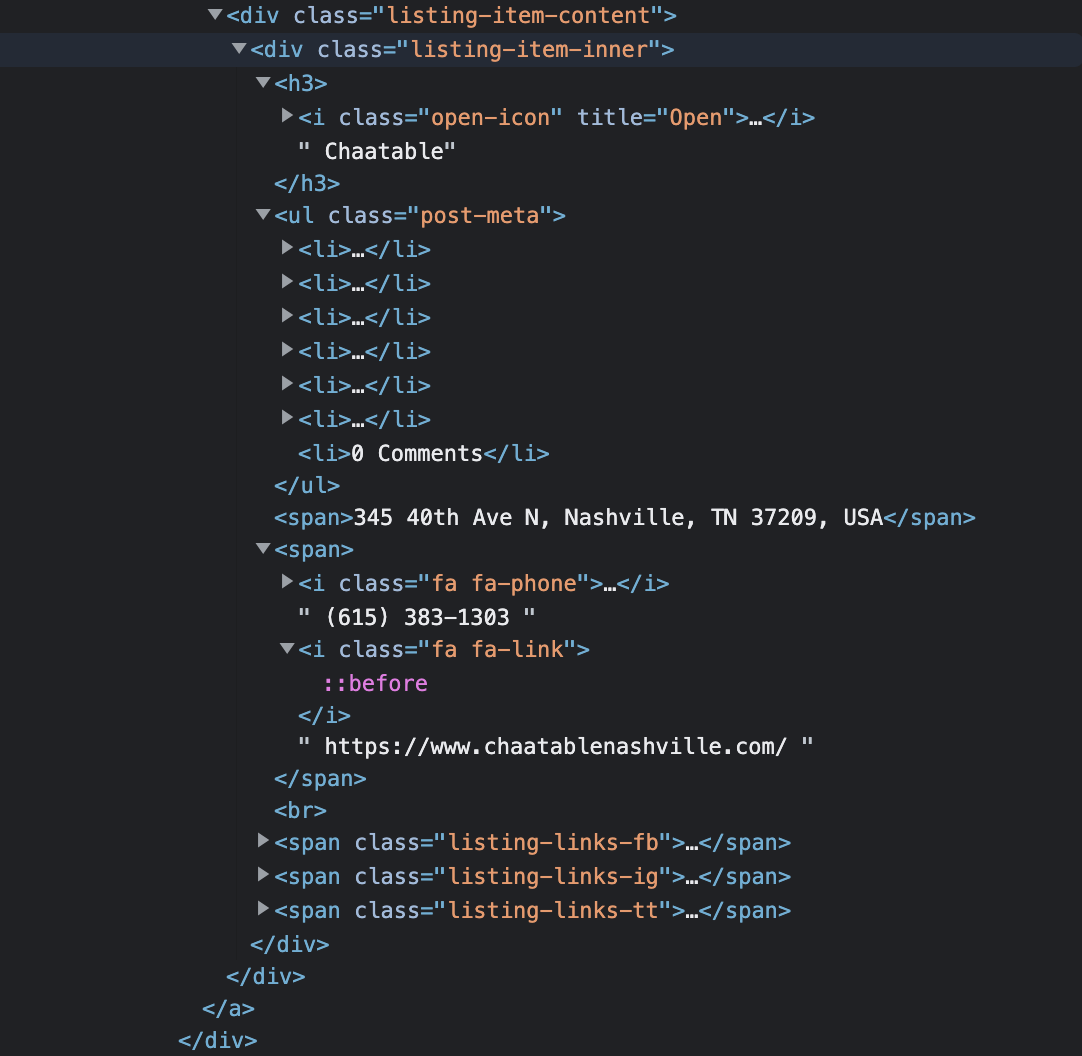
The desired output is to extract data from <span></span> where the 345 40th Ave N and the url below i class = 'fa fa-link' and i class = 'fa fa-phone' where the three elements are placed into a CSV File
CodePudding user response:
You could call next element e.find(class_ = 'fa-link').nextafter selecting the <i> with class fa-link:
for e in lists:
print(e.find(class_ = 'fa-link').next.strip() if e.find(class_ = 'fa-link') else '')
Note: Do not use reserved keywords like list and always check if element you are searching for is available.
Example
import requests
from bs4 import BeautifulSoup
url = 'https://www.flavortownusa.com/locations'
soup = BeautifulSoup(page.content, 'html.parser')
with open('somefile.csv', 'a', encoding='utf-8') as f:
for e in soup.find_all('div', class_ = 'listing-item-inner'):
title = e.h3.text
webs = e.select_one('.fa-link').next if e.select_one('.fa-link') else ''
address = e.span.text
phone = e.select_one('.fa-phone').next if e.select_one('.fa-phone') else ''
f.write(','.join([title, webs, address, phone]) '\n')