I have data in the below format, basically pairwise distance score of two string names:
Table A
name1 name2 score
xxx xxa 0.4
xxb xxc 0.2
xxd xxa 0.6
xxa zzz 0.8
I need the output in below format for e.g. for each name present in either in name1 or name2, taking the average of score by unique name in two columns. In the above table, xxa has score in 3 rows, so we take average and get a single score of 0.6
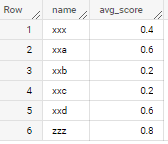
Output Table
name score
xxx 0.4
xxa 0.6
xxb 0.2
xxc 0.2
zzz 0.8
I am using the below query to get the result, it works for small data in bigquery, but my input table tableA is 900Million in size and the query just doesn't finish
with all_names as (
select distinct name1 as name from
tableA
union distinct
select distinct name2 as name from
tableA )
select name,avg(score) as avg_score
from tableA as a, all_names as b
where (b.name=a.name1 or b.name=a.name2)
group by 1
Is there any better efficient way to perform this operation?
CodePudding user response:
You might try below query:
SELECT name, ROUND(AVG(score), 1) avg
FROM tableA, UNNEST([name1, name2]) name
GROUP BY 1;
------ -----
| name | avg |
------ -----
| xxa | 0.6 |
| xxb | 0.2 |
| xxc | 0.2 |
| xxd | 0.6 |
| xxx | 0.4 |
| zzz | 0.8 |
------ -----
Or, if you prefer to use UNION,
SELECT name, ROUND(AVG(score), 1) avg
FROM (
SELECT name1 AS name, score FROM tableA
UNION ALL
SELECT name2 AS name, score FROM tableA
)
GROUP BY 1;
CodePudding user response:
Another option to consider
select name, avg(score) avg_score
from your_table
unpivot(name for col in (name1, name2))
group by name
if applied to sample data in your question - output is