I want to count unique IDs over all timestamps in the past per timestamp in case the last value of the ID is greater than 0 in a google BigQuery SQL.
I don't want to GROUP BY cause I need the whole table as output.
Also the table has > 1 billion rows so the query should be efficient.
Imagine I have a table like this:
| ID | value | timestamp |
|:-- | ----- | ----------:|
| A | 1 | 2021-01-01 |
| B | 0 | 2021-01-01 |
| C | 0 | 2021-01-01 |
| A | 0 | 2021-01-02 |
| B | 1 | 2021-01-02 |
| C | 1 | 2021-01-03 |
| B | 0 | 2021-01-04 |
the result should look like this:
| ID | value | timestamp | count_val_gt_0 |
|:-- | ----- | ---------- | --------------:|
| A | 1 | 2021-01-01 | 1 |
| B | 0 | 2021-01-01 | 1 |
| C | 0 | 2021-01-01 | 1 |
| A | 0 | 2021-01-02 | 1 |
| B | 1 | 2021-01-02 | 1 |
| C | 1 | 2021-01-03 | 2 |
| B | 0 | 2021-01-04 | 1 |
explanation:
timestamp - set of unique IDs with last value > 0
2021-01-01: {A}
2021-02-01: {B}
2021-03-01: {B,C}
2021-04-01: {C}
For timestamp 2021-01-01 only A has a value greater 0. No timestamp before that. For all rows with timestamp 2021-01-02 I'm counting unique IDs in case last value of this ID is greater than 0 over the timestamps 2021-01-01 and 2021-01-02. The last value of A is no longer greater than 0 but now B is. For timestamp 2021-01-03 last value of B is still greater 0, now also last value of C, so I'm counting 2. For timestamp 2021-01-04 B is no longer greater 0, so its just C: 1.
What I tried was following 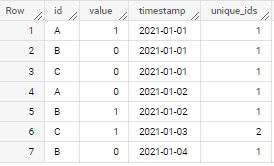
Please note:
- above is not tested and was written just as an example for alternative solution to address ">1 billion issue"
- while not fully tested - i did very quick one and looks like it works as expected and at least for dummy example in your question output is correct
- for small data, already proposed solution by Jaytiger is more effective. but for really big/heavy cases like yours - I think this approach has good chances to be more effective