Sorry if this is a repeat question or for the poor heading, I haven't been able to properly articulate in one line what I'm trying to find in a generic sense, so using the example below for what I'm trying to do.
I want to attain certain rows from a dataframe based on a min and max value from another dataframe. The min and max values are conditional on the group assigned:
data = {
'Name': ['John', 'John', 'Sam', 'Sam', 'Tim', 'Tim'],
'Salary': [18000, 20000, 15000, 35000, 12000, 30000]
}
boundary = {
'Name': ['John', 'Sam', 'Tim'],
'Min': [19000, 18000, 10000],
'Max': [21000, 30000, 32000]
}
data = pd.DataFrame(data, columns = ['Name', 'Salary'])
boundary = pd.DataFrame(boundary, columns = ['Name', 'Min', 'Max'])
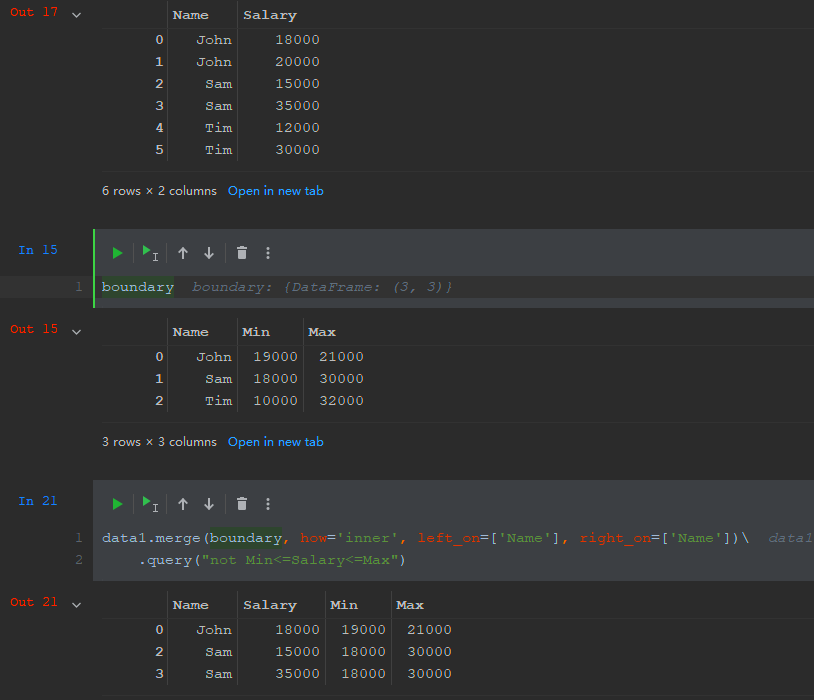
I want the result to be the below dataframe, where only the rows from the data df above the max and below the min from the boundary df are kept.
Name Salary
0 John 18000
2 Sam 15000
3 Sam 35000
I've been able to do this with a single min/max, but can't quite figure it out with the groups involved, thanks in advance.
CodePudding user response:
Merge in combination with query
data.merge(boundary, how="left", on="Name").query("Salary > Max or Salary < Min")[["Name", "Salary"]]
CodePudding user response:
One approach could be as follows:
- First, use
Please be sure to answer the question. Provide details and share your research!