I have recently been working with text files that contain data like the following:
A = a_0 a_1*x ... a_l*x^l
B = b_0 b_1*x ... b_m*x^m
.
.
.
G = g_2*x^2 g_n
where l and m are not necessarily the same, and B might not be the longest equation. Is there a way to import the coefficients into a NumPy array, inserting 0s where the coefficients are missing, such that the above example would yield
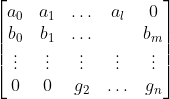
I was initially thinking of using numpy.genfromtxt where the x are filled with 1 (so that only the coefficient survives), but that has the problem that we lose which column and row the coefficient in. Any help is very much appreciated.
CodePudding user response:
This is very custom type of text you have to write a parser to do so:
considering the txt file is read, example here s
you probably have to read from file, with open('..') as fid ...
s = """A = 2*x 3*x^5
B = 3 2*x 3*x^5
C = 8 20*x 3*x^9"""
like this:
equations = s.split('\n')
def parse_lines(s):
def foo(val):
coef, _power,*_ = *val.split('*'), '^' # parse a_0*x^n
x, power, *_ = *_power.split('^'), '1' # parse x^n
power = 0 if not power else power
return int(coef) , int(power)
_, eq = s.split('=')
return [foo(item) for item in eq.split(' ')]
indexes = [(idx, *t) for idx, eq in enumerate(equations) for t in parse_lines(eq)]
output: (row, val, col)
[(0, 2, 1),
(0, 3, 5),
(1, 3, 0),
(1, 2, 1),
(1, 3, 5),
(2, 8, 0),
(2, 20, 1),
(2, 3, 9)]
you could parse to a format that could be reconstructed to an array. after this it is simple just build array:
m, _, n = np.array(d).max(axis=0)
m , n = m 1, n 1
arr = np.zeros((m,n))
for row, val, col in indexes:
arr[row, col] = val
output:
array([[ 0., 2., 0., 0., 0., 3., 0., 0., 0., 0.],
[ 3., 2., 0., 0., 0., 3., 0., 0., 0., 0.],
[ 8., 20., 0., 0., 0., 0., 0., 0., 0., 3.]])