I have a pandas dataframe, and I need to "switch" row and columns. (transpose ? pivot ? melt ? no idea how is it called) :
Let's say I have 2 references, each reference has 4 steps, each step has 3 variables
df = pd.DataFrame({'ref': ['ref1', 'ref1', 'ref1', 'ref1', 'ref2', 'ref2', 'ref2', 'ref2'],
'step': [1, 2, 3, 4, 1, 2, 3, 4],
'var_1': [5, 7, 7, 9, 12, 9, 87, 90],
'var_2': [11, 8, 10, 6, 6, 9, 12, 9],
"var_3": [11, 8, 10, 6, 6, 9, 12, 9]})
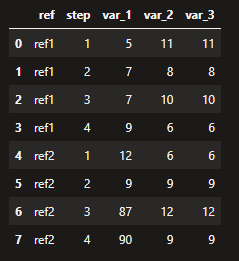
I want to transform this df to this form :
df = pd.DataFrame({'ref': ['ref1', 'ref2'],
> 'step 1 - var_1': [5, 12],
> 'step 1 - var_2': [11, 6],
> 'step 1 - var_3': [11, 6],
> 'step 2 - var_1': [7, 12],
> 'step 2 - var_2': [8, 9],
> 'step 2 - var_3': [8, 9]})

Thank you in advance, Best
edit : format and images
CodePudding user response:
Try this using the new "walrus" operator in a one-liner:
(df_new := df.set_index(['ref', 'step']).unstack().sort_index(level=1, axis=1))\
.set_axis([f'step {j} - {i}' for i, j in df_new.columns], axis=1)
Output:
step 1 - var_1 step 1 - var_2 step 1 - var_3 step 2 - var_1 step 2 - var_2 step 2 - var_3 step 3 - var_1 step 3 - var_2 step 3 - var_3 step 4 - var_1 step 4 - var_2 step 4 - var_3
ref
ref1 5 11 11 7 8 8 7 10 10 9 6 6
ref2 12 6 6 9 9 9 87 12 12 90 9 9
Details:
set_indexwith columns ref and stepunstackstep to move into columns- Order you columns uinsg
sort_index - flatten multiindex dataframe column headers using
set_axisand list comprehension with f-string formatting
Alternative way with same out put with order as above,
df_out = df.pivot(index='ref', columns='step').sort_index(level=1, axis=1)
df_out.columns = [f'step {j} - {i}' for i, j in df_out.columns]
CodePudding user response:
One option is with pivot_wider from pyjnanitor, to abstract the column renaming via the names_glue parameter:
# pip insall pyjanitor
import pandas as pd
import janitor
(df
.pivot_wider(
index='ref',
names_from='step',
values_from = ['var_1', 'var_2', 'var_3'],
names_glue = "step {step} - {_value}")
.sort_index(axis=1)
)
ref step 1 - var_1 step 1 - var_2 step 1 - var_3 ... step 3 - var_3 step 4 - var_1 step 4 - var_2 step 4 - var_3
0 ref1 5 11 11 ... 10 9 6 6
1 ref2 12 6 6 ... 12 90 9 9
[2 rows x 13 columns]
names_glue allows a combination of the values_from and names_from parameters - in the code above {step} is the names_from argument, while {_value} is a placeholder for values_from
If we stick strictly to your output, then a filter should be executed on the step column for only values less than 3:
(df
.loc[df.step < 3]
.pivot_wider(
index='ref',
names_from='step',
names_glue = "step {step} - {_value}")
.sort_index(axis=1)
)
ref step 1 - var_1 step 1 - var_2 step 1 - var_3 step 2 - var_1 step 2 - var_2 step 2 - var_3
0 ref1 5 11 11 7 8 8
1 ref2 12 6 6 9 9 9
CodePudding user response:
Use:
df[df.step<3].set_index(['ref','step']).unstack()
output:
var_1 var_2 var_3
step 1 2 1 2 1 2
ref
ref1 5 7 11 8 11 8
ref2 12 9 6 9 6 9
CodePudding user response:
The trick is to use df.pivot. You can choose the index='ref' and columns='step':
new = df.pivot(index='ref', columns='step')
The resulting table has a multi-index for ref and a multi-column. The multi-column has the step and var information, so we can use that to make the new column headers. Finally, we can reset the index:
new.columns = [f'step {x[1]} - {x[0]}' for x in new.columns]
new = new.reset_index()