I want to extract the product href attribute from this 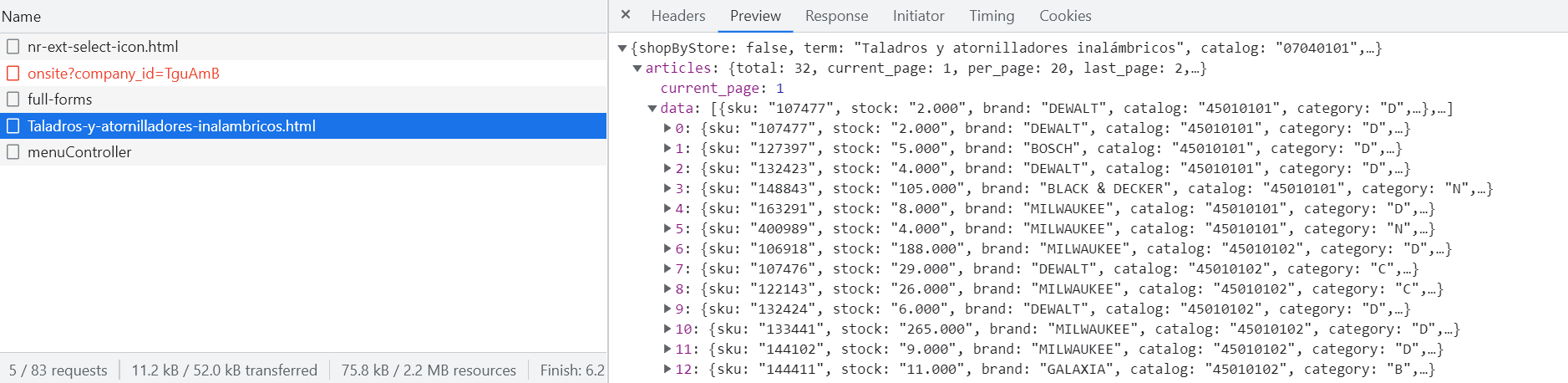
Code and example in the online IDE:
import requests
# Dev tools -> Network -> Fetch/XHR -> Headers -> Request Headers (list)
headers = {
"x-requested-with": "XMLHttpRequest", # only this request header matter, otherwise it will throw an error
}
# https://docs.python-requests.org/en/master/user/quickstart/#json-response-content
response = requests.get("https://www.vidri.com.sv/catalogo/07040101/Taladros-y-atornilladores-inalambricos.html", headers=headers).json()
for result in response["articles"]["data"]:
sku = result["sku"]
title = result["title"]
price = int(float(result["price"])) # gets rid of floating number: "300.00000000"
print(f"{sku}\n{title}\n{price}\n")
# part of the output
'''
107477
Taladro inalámbrico 1/2 pulg 20v brushless cd791d2-b3
300
127397
Taladro atornillador 3/8" inalambrico bosch gsr 12v-15 fc1
225
132423
Taladro inalámbrico 3/8 pulg 12v dcd700c2-b3
175
'''
P.S. There's a dedicated web scraping blog of mine. If you need to parse search engines, have a try using SerpApi.
Disclaimer, I work for SerpApi.