The groups of my data frame are defined by two indexed columns (cat1 and cat2). For a third, non-indexed variable, var, I want to find the index cat2, for max value of var for each value of cat1.
When I use idxmax(), I get the overall index value of both cat1 and cat2 corresponding to max value of var which is (B,dog). I want this value for each level of cat1.
df = pd.DataFrame({
'cat1': ['A'] * 4 ['B'] * 4 ['C'] * 4,
'cat2': ['cat', 'dog', 'mouse', 'bear'] * 3,
'var': [23, 33, 45, 66, 77, 88, 44, 55, 33, 22, 11, 44],
}).set_index(['cat1', 'cat2'])
var
cat1 cat2
A cat 23
dog 33
mouse 45
bear 66
B cat 77
dog 88
mouse 44
bear 55
C cat 33
dog 22
mouse 11
bear 44
This is the result produced:
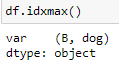
Desired results:

I don't care about the format.
CodePudding user response:
Use groupby.idxmax:
df.groupby('cat1').idxmax() # or df.groupby(level=0).idxmax()
# var
# cat1
# A (A, bear)
# B (B, dog)
# C (C, bear)
- Your current code uses
DataFrame.idxmax, which returns the index of the global max. - However you just want the index of each group's max, so use
groupby.idxmax.
(In the future, please provide sample dataframes as copy-pastable code rather than as images, as sammywemmy said.)
CodePudding user response:
There are infinite ways to create the output of this code. I demonstrated below 3 ways:
MaxEachcat1 = df[df['var'] == df.groupby(level=[0])['var'].transform(max)]
print(MaxEachcat1)
print(MaxEachcat1.index)
print(MaxEachcat1.index[0])
output:
# way 1
var
cat1 cat2
A bear 66
B dog 88
C bear 44
# way 2
MultiIndex([('A', 'bear'),
('B', 'dog'),
('C', 'bear')],
names=['cat1', 'cat2'])
# way 3
('A', 'bear')