import pandas as pd
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
phoneList = []
nameList = []
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
df = pd.DataFrame({'Phone Number': phoneList, 'Name': nameList})
df.to_csv('results.csv', index=False, encoding='utf-8')
print(df)
What I want to do is retrieve from this list1 is each phone number and put that into the phoneList.
From there I want to see if there is a name from the nameBank that is in the list after the current phone number and before the next phone number in the list.
If there is a name after a phone number, then I want to be able to append it to the nameList,
if there is no name after a phone number, then i want to append "No Name Found" to the nameList.
So it can essentially correspond in an excel chart.
i.e the phone number 1234567890 has the name John Doe corresponding to it between the two lists. The second phone number has the name Jane Doe attached to it so when you use these two lists to create a table using pandas they will correspond.
The third phone number 3456789012 has no name in between itself and the next phone number in the list, therefore I want the appended value to the nameList to be "no name found".
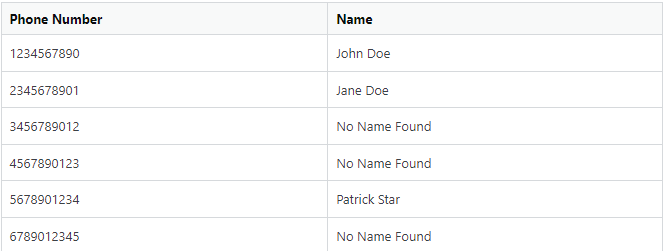
Essentially what the output table would look like:
CodePudding user response:
So, you want to parse list1 into a Series:
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
import re
num = re.compile('\d{10}')
output = {}
i = 0
while i < len(list1):
if not num.match(list1[i]):
i = 1
continue
output[list1[i]] = list1[i 1] if i 1<len(list1) and not num.match(list1[i 1]) else 'not found'
i = 1
series = pd.Series(output)
Output:
1234567890 John doe
2345678901 jane doe
3456789012 not found
4567890123 not found
5678901234 patrick star
6789012345 not found
dtype: object
CodePudding user response:
import pandas as pd
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
data = []
for index, elem in enumerate(list1):
if elem.isnumeric():
if (len(list1) - 1) > index:
if list1[index 1].casefold() in map(str.casefold, nameBank):
data.append([elem,list1[index 1].title()])
else:
data.append([elem, 'No Name Found'])
else:
data.append([elem, 'No Name Found'])
df = pd.DataFrame(data, columns=['Phone Number', 'Name'])
# df.to_csv('results.csv', index=False, encoding='utf-8'
print(df)
output:
Phone Number Name
0 1234567890 John Doe
1 2345678901 Jane Doe
2 3456789012 No Name Found
3 4567890123 No Name Found
4 5678901234 Patrick Star
5 6789012345 No Name Found
CodePudding user response:
import re
import pandas as pd
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
def mapList(list1):
output = []
for index, item in enumerate(list1, start=0):
if re.match("^\d{10}", item):
# Use any one condition
# if index < len(list1) - 1 and list1[index 1] in nameBank:
if index < len(list1) - 1 and not re.match("^\d{10}", list1[index 1]):
output.append([list1[index], list1[index 1]]);
else:
output.append([list1[index],'No Name Found']);
return output;
df = pd.DataFrame(mapList(list1), columns=['Phone Number', 'Name'])
print(df)
Output:
Phone Number Name
0 1234567890 John doe
1 2345678901 jane doe
2 3456789012 No Name Found
3 4567890123 No Name Found
4 5678901234 patrick star
5 6789012345 No Name Found