I have a large DataFrame with 50 columns which I'm simplifying here below:
students = [('Samurai', 34, '777.0', 'usa--->jp', 'usd--->yen') ,
('Jack', 31, '555.5','usa','usd') ,
('Mojo', 16,'488.1','n/a','n/a') ,
('Jojo', 32,'119.11','uk--->usa','pound--->usd')]
# Create a DataFrame object
df = pd.DataFrame(students, columns=['Name', 'Age', 'Balance', 'Country','Currency'])
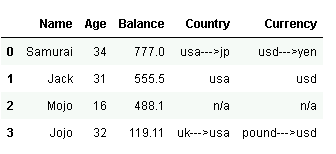
I'm trying to find
a) whether there are any instances of '--->' in any of the cells across the DataFrame?
b) if so where? (optional)
So far I've tried 2 approaches
boolDf = df.isin(['--->']).any().any()
this only works for strings not substrings
columns = list(df)
for col in columns:
df[col].str.find('--->', 0).any()
I get:
AttributeError: Can only use .str accessor with string values!
(I believe this may only work for columns with string types)
Would appreciate any help. Open to other approaches as well.
CodePudding user response:
You could do:
df.apply(lambda x: x.str.contains('--->').any(), axis=1)
0 True
1 False
2 False
3 True
CodePudding user response:
You could apply str.contains for each column to identify which cell contains a particular string:
out = df.astype(str).apply(lambda col: col.str.contains('--->'))
Output:
Name Age Balance Country Currency
0 False False False True True
1 False False False False False
2 False False False False False
3 False False False True True
Then out.any().any() will produce True.
As a one-liner:
df.astype(str).apply(lambda col: col.str.contains('--->')).any().any()
CodePudding user response:
Try this:
boolDf = df['Country'].where(df['Country'].str.contains('--->'))
df_filter=boolDf.isnull()
df[~df_filter]
CodePudding user response:
import pandas as pd
students = [('Samurai', 34, '777.0', 'usa--->jp', 'usd--->yen') ,
('Jack', 31, '555.5','usa','usd') ,
('Mojo', 16,'488.1','n/a','n/a') ,
('Jojo', 32,'119.11','uk--->usa','pound--->usd')]
# Create a DataFrame object
df = pd.DataFrame(students, columns=['Name', 'Age', 'Balance', 'Country','Currency'])
def find_substr(df:pd.DataFrame,substr:str) -> pd.DataFrame:
"""
df: pd.DataFrame we want to search
substr: the string that we are looking for in all string columns
returns df of boolean values
"""
# create new df to house bool values (if substring is found)
new_df = pd.DataFrame()
# loop through the columns
for col in df.columns:
# if the series is a string we will search for it
if pd.api.types.is_string_dtype(df[col]):
# the series of our new df represent if we found the substring
new_df[col] = df[col].str.contains(substr)
return new_df
found_str = find_substr(df,'--->')
found_str
# -- OUTPUT --
Name Balance Country Currency
0 False False True True
1 False False False False
2 False False False False
3 False False True True
This function should work it gives you a new df of boolean values for each cell where you found the substring.
edit:
This uses pd.Series.str.contains() to find each string that contains your substring. Read more here: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.contains.html