I wrote a python script in lambda, in which I am fetching S3 CSV files and putting data into DynamoDb. Everything is going great but I want to skip the 0 index of my loop and don't know how to perform that action in my situation. Following is my code:
import json
import boto3
s3_client = boto3.client("s3")
dynamodb = boto3.resource("dynamodb")
student_table = dynamodb.Table('s3todynamodb')
def lambda_handler(event, context):
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
file_name = event['Records'][0]['s3']['object']['key']
file_object = s3_client.get_object(Bucket=source_bucket_name,Key=file_name)
print("file_object :",file_object)
file_content = file_object['Body'].read().decode("utf-8")
print("file_content :",file_content)
students = file_content.split("\n")
print("students :",students)
for student in students:
data = student.split(",")
print(data[0])
print(data[1])
print(data[2])
print(data[3])
print(data[4])
print(data[5])
print(data[6])
print(data[7])
print(data[8])
print(data[9])
print(data[10])
print(data[11])
print(data[12])
print(data[13])
print(data[14])
print(data[15])
print(data[16])
print(data[17])
print(data[18])
student_table.put_item(
Item = {
"Agent" : data[0],
"Agent answer rate" : data[1],
"Agent idle time" : data[2],
"Contacts missed" : data[3],
"Agent on contact time" : data[4],
"Nonproductive time" : data[5],
"Occupancy" : data[6],
"Online time" : data[7],
"Average after contact work time" : data[8],
"Average agent interaction time" : data[9],
"Average customer hold time" : data[10],
"Average handle time" : data[11],
"Contacts handled" : data[12],
"Contacts handled incoming" : data[13],
"Contacts handled outbound" : data[14],
"Contacts put on hold" : data[15],
"Contacts transferred out" : data[16],
"Contacts transferred out external" : data[17],
"Contacts transferred out internal" : data[18]
}
)
There is also second issue while running this code, although it is working properly but every time it executes, it throws an error that is mentioned below:
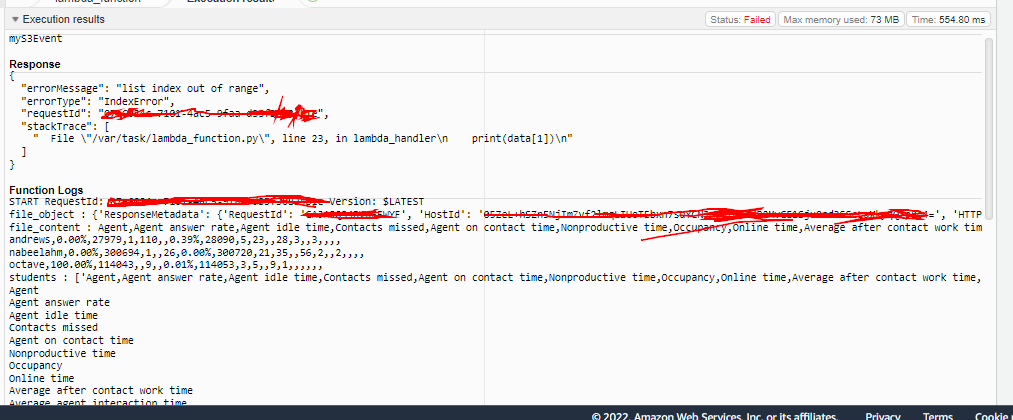
First problem = Start for loop from 1 Second problem = Index list out of range error.
I would be very grateful if anyone provides any help. Thanks in advance.
CodePudding user response:
You almost assuredly are hitting on an empty line, causing your final student.split(",") to return a one element array.
Rather than parsing the CSV manually, it would be much easier to use the built-in Python module to parse it for you:
from csv import DictReader
from io import StringIO
for Item in DictReader(StringIO(file_content)):
print(Item)
CodePudding user response:
For the fist one you can do:
for student in students[1:]:
The second issue is on line 23, which is one of the
print(data[X])
Not quite sure which one exactly, as your code doesn't show lines. You have to print out the data (without index) to check for sure.