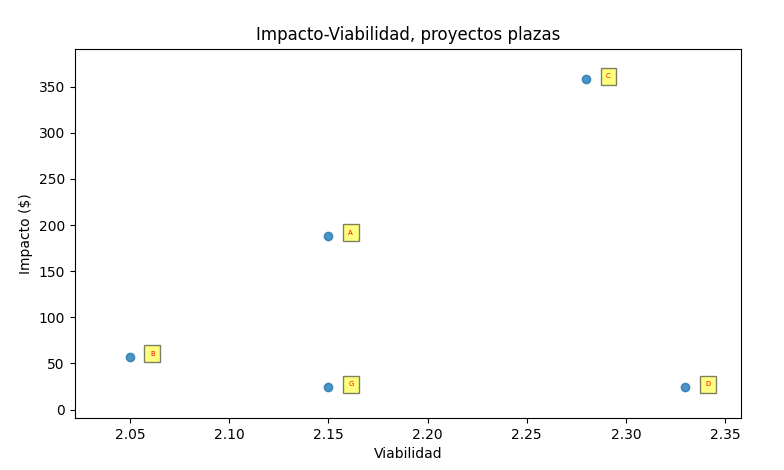
I have the following data frame:
dic_projects = {
'Proyectos' :['A','B','C', 'D','E','F','G'],
'Impacto' :[188,57,358,24, None, None,24],
'Viabilidad':[2.15,2.05,2.28,2.33, 1.6, 1.91, 2.15]
}
df = pd.DataFrame(dic_projects)
And I would like to use a scatter plot with seaborn
sns.regplot(x=df['Viabilidad'], y=df['Impacto'], ci=False, fit_reg=False)
for i in range(df.shape[0]):
plt.text(x=df['Impacto'][i] 0.3, y=df['Viabilidad'][i] 0.3, s=df['Proyectos'][i],
fontdict=dict(color='red',size=5),
bbox=dict(facecolor='yellow',alpha=0.5))
plt.title('Impacto-Viabilidad, proyectos plazas')
plt.xlabel('Viabilidad')
plt.ylabel('Impacto ($)')
plt.show()
But I get the ValueError: Image size pixels is too large. Thanks in advance.
CodePudding user response:
Is this what you want?
import pandas as pd
import matplotlib.pyplot as plt
dic_projects = {
'Proyectos' :['A','B','C', 'D','E','F','G'],
'Impacto' :[188,57,358,24, None, None,24],
'Viabilidad':[2.15,2.05,2.28,2.33, 1.6, 1.91, 2.15]
}
df = pd.DataFrame(dic_projects)
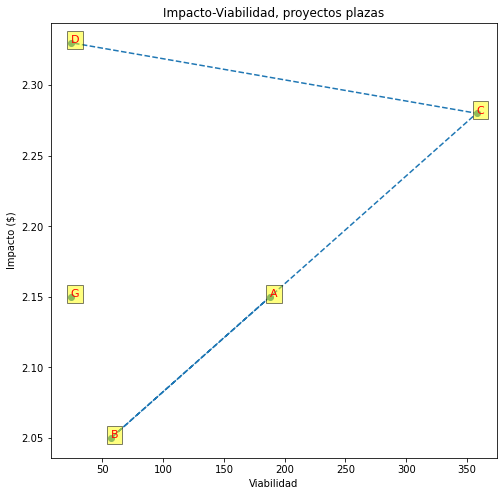
plt.figure(figsize=(8,8))
plt.plot(df['Impacto'], df['Viabilidad'], '--o')
for i in range(df.shape[0]):
plt.text(x=df['Impacto'][i], y=df['Viabilidad'][i], s=df['Proyectos'][i],
fontdict=dict(color='red',size=11),
bbox=dict(facecolor='yellow',alpha=0.5))
plt.title('Impacto-Viabilidad, proyectos plazas')
plt.xlabel('Viabilidad')
plt.ylabel('Impacto ($)')
plt.show()
CodePudding user response:
There are 3 problems:
xandyare switched between the call tosns.regplotand toplt.text()- plotting the text needs a test to filter out
NaNs. - the distance of 0.3 is too high in the x-direction
Apart from that, the margins could be enlarged a bit to fit all the texts.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
dic_projects = {'Proyectos': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'Impacto': [188, 57, 358, 24, None, None, 24],
'Viabilidad': [2.15, 2.05, 2.28, 2.33, 1.6, 1.91, 2.15]}
df = pd.DataFrame(dic_projects)
ax = sns.regplot(x=df['Viabilidad'], y=df['Impacto'], ci=False, fit_reg=False)
for i in range(df.shape[0]):
print(i, df['Impacto'][i], df['Viabilidad'][i])
if not (np.isnan(df['Impacto'][i]) or np.isnan(df['Viabilidad'][i])):
print('>', df['Impacto'][i], df['Viabilidad'][i], df['Proyectos'][i])
ax.text(x=df['Viabilidad'][i] 0.01, y=df['Impacto'][i] 0.3, s=df['Proyectos'][i],
fontdict=dict(color='red', size=5), va='bottom',
bbox=dict(facecolor='yellow', alpha=0.5))
ax.set_title('Impacto-Viabilidad, proyectos plazas')
ax.set_xlabel('Viabilidad')
ax.set_ylabel('Impacto ($)')
ax.margins(x=0.1, y=0.1) # increase margins
plt.show()