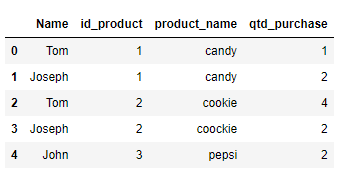
The following dataset is a minor representation of an example of the problem I am facing:
data = {'Name': ['Tom', 'Joseph', 'Tom', 'Joseph', 'John'], 'id_product': [1, 1, 2, 2, 3],
'product_name': ["candy", "candy", "cookie", "coockie", "pepsi"], 'qtd_purchase': [1, 2, 4, 2, 2]}
the pandas form:
The problem is that, for example, if we look at the unique values of each column we will find the following error:
for col in data.columns:
if not 'no' in col and not 'code' in col and not 'id' in col:
un_n = data[col].nunique()
print(f'n of unique {col}: {un_n}')
n of unique Name: 3
n of unique product_name: 4
n of unique qtd_purchase: 3
the id_product should have the same number of product_name. But because of a typo mistake, we have items with the same code and different names. For example, "cookie" and "cookie".
I was able to find these items using the following code:
pd.options.display.max_rows = None
data.groupby(['id_product', 'product_name']).count()['qtd_purchase']

For that scale, this code solves just fine. But in my real problem, I have 21000 unique id_products and 23000 product_name. It becomes impossible to identify them using the code above. Would there be any way to just print the values that are badly written?
For example, the answer would look like this:
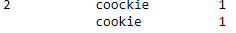
Thank you very much in advance
CodePudding user response:
Here's a possible approach.
data = {'Name': ['Tom', 'Joseph', 'Tom', 'Joseph', 'John'], 'id_product': [1, 1, 2, 2, 3],
'product_name': ["candy", "candy", "cookie", "coockie", "pepsi"], 'qtd_purchase': [1, 2, 4, 2, 2]}
df = pd.DataFrame(data)
print(df.loc[:,['id_product','product_name']].groupby(
'id_product').filter(
lambda g:any(g.nunique()>1)))
Result:
id_product product_name
2 2 cookie
3 2 coockie
CodePudding user response:
You can try to use groupby on the id_product column and then count the values of each product:
df.groupby("id_product").product_name.value_counts()
For your example, this will return:
id_product product_name
1 candy 2
2 coockie 1
cookie 1
3 pepsi 1
This could help you to learn more about your data. If we assume that the misspellings happen only occasionally, you can get the most common spelling for each id with mode(). Let's add another purchase...
data = {'Name': ['Tom', 'Joseph', 'Tom', 'Joseph', 'John', "Cookie monster"],
'id_product': [1, 1, 2, 2, 3, 2],
'product_name': ["candy", "candy", "cookie", "coockie", "pepsi", "cookie"],
'qtd_purchase': [1, 2, 4, 2, 2, 42]}
df = pd.DataFrame(data)
df.head(6)
gives
Name id_product product_name qtd_purchase
0 Tom 1 candy 1
1 Joseph 1 candy 2
2 Tom 2 cookie 4
3 Joseph 2 coockie 2
4 John 3 pepsi 2
5 Cookie monster 2 cookie 42
and then:
>>> df.groupby("id_product").product_name.apply(pd.Series.mode)
id_product
1 0 candy
2 0 cookie
3 0 pepsi
Name: product_name, dtype: object