I built a random forest by RandomForestClassifier and plot the decision trees. What does the parameter "value" (pointed by red arrows) mean? And why the sum of two numbers in the [] doesn't equal to the number of "samples"? I saw some other examples, the sum of two numbers in the [] equals to the number of "samples". Why in my case, it doesn't?
df = pd.read_csv("Dataset.csv")
df.drop(['Flow ID', 'Inbound'], axis=1, inplace=True)
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.dropna(inplace = True)
df.Label[df.Label == 'BENIGN'] = 0
df.Label[df.Label == 'DrDoS_LDAP'] = 1
Y = df["Label"].values
Y = Y.astype('int')
X = df.drop(labels = ["Label"], axis=1)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5)
model = RandomForestClassifier(n_estimators = 20)
model.fit(X_train, Y_train)
Accuracy = model.score(X_test, Y_test)
for i in range(len(model.estimators_)):
fig = plt.figure(figsize=(15,15))
tree.plot_tree(model.estimators_[i], feature_names = df.columns, class_names = ['Benign', 'DDoS'])
plt.savefig('.\\TheForest\\T' str(i))
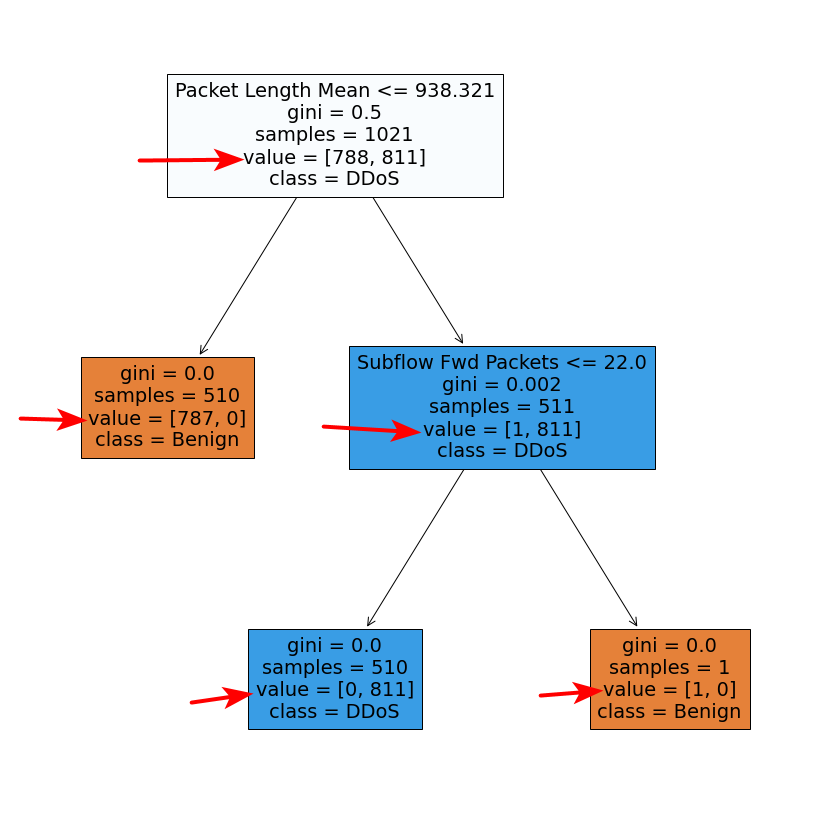
CodePudding user response:
Nice catch.
Although undocumented, this is due to the bootstrap sampling taking place by default in a Random Forest model (see my answer in 
The result here is similar to what you report: for every other node except the lower right one, sum(value) does not equal samples, as it should be the case for 
Well, now that we have disabled bootstrap sampling, everything looks "nice": the sum of value in every node equals samples, and the base node contains indeed the whole dataset (150 samples).
So, the behavior you describe seems to be due to bootstrap sampling indeed, which, while creating samples with replacement (i.e. ending up with duplicate samples for each individual decision tree of the ensemble), these duplicate samples are not reflected in the sample values of the tree nodes, which display the number of unique samples; nevertheless, it is reflected in the node value.
The situation is completely analogous with that of a RF regression model - see own answer in sklearn RandomForestRegressor discrepancy in the displayed tree values.