I am trying to plot a population category inside the whole population.
So if I have:
df <- data.frame (population= c("a", "a", "a", "a","b", "b","b","b","c","c"),
income= c("10", "15", "12", "19","45", "42","41","43","23","23")
)
How can I plot the proportion of "a" from the whole df in a density plot? Like in the following picture:
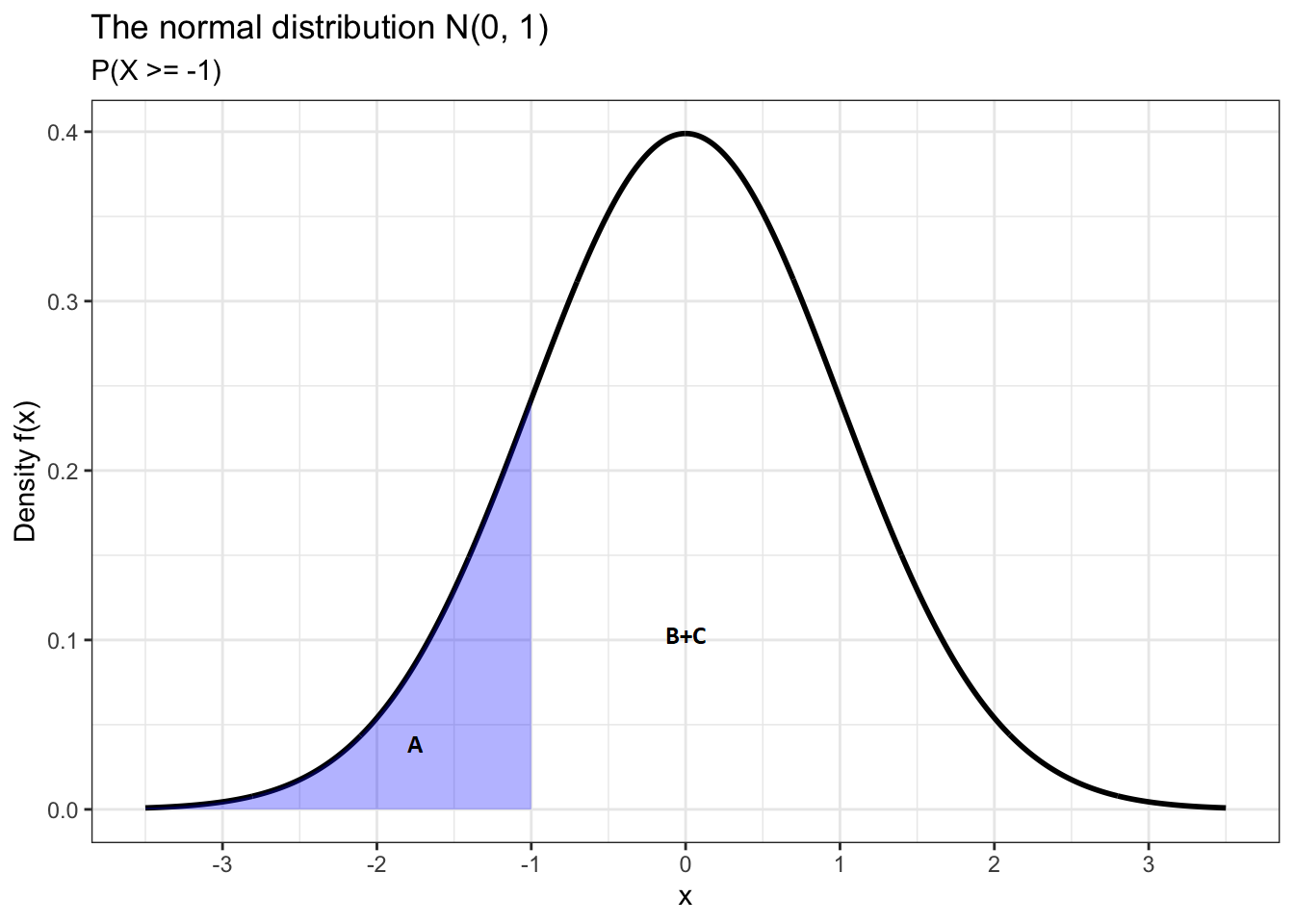
EDIT
What I am trying to plot is the density of the values a, b and c. Not the income values. And inside this density plot, I want to shadow only the 'a' values. Basically, I want to shadow in a density plot the proportion of a value from a dataframe column.
This is the link of the dataset I am working on. I want to plot the proportion of the value "Self-Employed" in the "workclass" variable.
CodePudding user response:
your question is not clear indeed. But maybe you meant something like this
hist(as.numeric(df[df$population=='a','income']), freq = F)
CodePudding user response:
Finally, I found a link in S.O.. This is my final code:
ggplot(censo, aes(x = factor(workclass)))
geom_bar(aes(y = (..count..)/sum(..count..)))
scale_y_continuous(labels = percent)