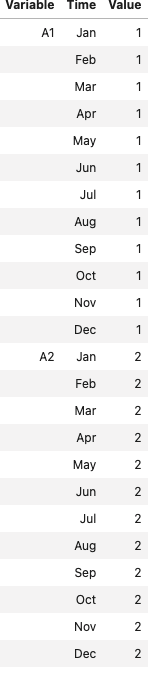
So I have a CSV file that has data in the following manner:
|Variable |Time |Value|
|A1 |Jan | 33 |
| |Feb | 21 |
| |Mar | 08 |
| |Apr | 17 |
| |May | 04 |
| |Jun | 43 |
| |Jul | 40 |
| |Aug | 37 |
| |Sep | 30 |
| |Oct | 46 |
| |Nov | 10 |
| |Dec | 13 |
| B1 |Jan | 20 |
| |Feb | 11 |
| |Mar | 02 |
| |Apr | 18 |
| |May | 10 |
| |Jun | 35 |
| |Jul | 45 |
| |Aug | 32 |
| |Sep | 39 |
| |Oct | 42 |
| |Nov | 15 |
| |Dec | 18 |
Like this it goes on until A10 and B10.
I need only A with time from Jan to Dec along with the values and drop values corresponding to B. How to do it? What will be the condition?
CodePudding user response:
Two different methods:
If the column widths are fixed:
df = pd.read_fwf('file.csv', colspecs=[(1,9), (11,16), (17, 22)])
df = df[df.replace('', np.nan).ffill()['Variable'].str.startswith('A')]
print(df)
Output:
Variable Time Value
0 A1 Jan 33
1 Feb 21
2 Mar 8
3 Apr 17
4 May 4
5 Jun 43
6 Jul 40
7 Aug 37
8 Sep 30
9 Oct 46
10 Nov 10
11 Dec 13
If things are more dirty:
with open('file.csv', 'r') as f:
df = pd.DataFrame([[y.strip() for y in x.split('|')[1:4]] for x in f.readlines() if x.strip()])
df.columns = df.iloc[0].values
df = df.drop(0).reset_index(drop=True)
df['Value'] = pd.to_numeric(df['Value'])
print(df)
Output:
Variable Time Value
0 A1 Jan 33
1 Feb 21
2 Mar 8
3 Apr 17
4 May 4
5 Jun 43
6 Jul 40
7 Aug 37
8 Sep 30
9 Oct 46
10 Nov 10
11 Dec 13
12 B1 Jan 20
13 Feb 11
14 Mar 2
15 Apr 18
16 May 10
17 Jun 35
18 Jul 45
19 Aug 32
20 Sep 39
21 Oct 42
22 Nov 15
23 Dec 18
CodePudding user response:
Assuming your data is arranged as you described, with some extrapolation as below
Use pandas' ffill() to impute the variable column to facilitate the desired selection as below.
sample = pd.read_csv('sample.csv')
sample['Variable'].ffill(axis=0,inplace=True)
sample = sample.loc[sample['Variable'].str.startswith('A')]
n_months = 12
indexes_to_impute_as_empty = list(range(0,len(sample),n_months))
sample.loc[indexes_to_impute_as_empty,'temp_Variable'] = sample.loc[indexes_to_impute_as_empty,'Variable']
sample['Variable'] = sample['temp_Variable']
sample.drop(columns=['temp_Variable'],inplace=True)
sample.replace(np.nan,"",inplace=True)
sample