Lately, I have been trying to pivot a table in snowflake and replicate a transformation operation in snowflake which is presently being done in pandas like the following:
I have a dataframe like the below:
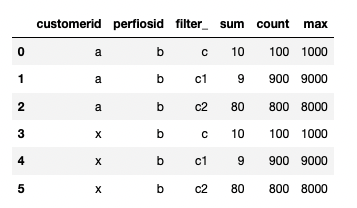
I have been able to convert this into the following format:

Using code below:
dd = pd.pivot(df[['customerid', 'filter_', 'sum', 'count', 'max']], index='customerid', columns='filter_')
dd = dd.set_axis(dd.columns.map('_'.join), axis=1, inplace=False).reset_index()
I have been trying to do this in snowflake but am unable to get the same format. Here's what I have tried:
with temp as (
SELECT $1 as customerid, $2 as perfiosid, $3 as filter_, $4 as sum_, $5 as count_, $6 as max_
FROM
VALUES ('a', 'b', 'c', 10, 100, 1000),
('a', 'b', 'c1', 9, 900, 9000),
('a', 'b', 'c2', 80, 800, 8000),
('x', 'b', 'c', 10, 100, 1000),
('x', 'b', 'c1', 9, 900, 9000),
('x', 'b', 'c2', 80, 800, 8000))
,
cte as (
select *, 'SUM_' as idx
from temp pivot ( max(sum_) for filter_ in ('c', 'c1', 'c2'))
union all
select *, 'COUNT_' as idx
from temp pivot ( max(count_) for filter_ in ('c', 'c1', 'c2'))
union all
select *, 'MAX_' as idx
from temp pivot ( max(max_) for filter_ in ('c', 'c1', 'c2'))
order by customerid, perfiosid
)
-- select * from cte;
select customerid, perfiosid, idx, max("'c'") as c, max("'c1'") as c1, max("'c2'") as c2
from cte
group by 1, 2, 3
order by 1, 2, 3
The output I get from this is:
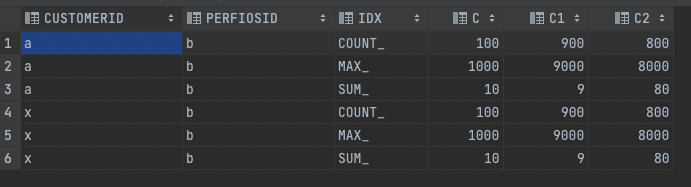
Note: I have 3k fixed filters per customerid and 18 columns like sum, count, max, min, stddev, etc. So the final output must be 54k columns for each customerid. How can I achieve this while being within the limits of 1 MB statement execution of snowflake?
CodePudding user response:
Using conditional aggregation:
with temp as (
SELECT $1 as customerid, $2 as perfiosid, $3 as filter_, $4 as sum_, $5 as count_, $6 as max_
FROM
VALUES ('a', 'b', 'c', 10, 100, 1000),
('a', 'b', 'c1', 9, 900, 9000),
('a', 'b', 'c2', 80, 800, 8000),
('x', 'b', 'c', 10, 100, 1000),
('x', 'b', 'c1', 9, 900, 9000),
('x', 'b', 'c2', 80, 800, 8000)
)
SELECT customerid,
SUM(CASE WHEN FILTER_ = 'c' THEN SUM_ END) AS SUM_C,
SUM(CASE WHEN FILTER_ = 'c1' THEN SUM_ END) AS SUM_C1,
SUM(CASE WHEN FILTER_ = 'c2' THEN SUM_ END) AS SUM_C2,
SUM(CASE WHEN FILTER_ = 'c' THEN COUNT_ END) AS COUNT_C,
SUM(CASE WHEN FILTER_ = 'c1' THEN COUNT_ END) AS COUNT_C1,
SUM(CASE WHEN FILTER_ = 'c2' THEN COUNT_ END) AS COUNT_C2,
MAX(CASE WHEN FILTER_ = 'c' THEN MAX_ END) AS MAX_C,
MAX(CASE WHEN FILTER_ = 'c1' THEN MAX_ END) AS MAX_C1,
MAX(CASE WHEN FILTER_ = 'c2' THEN MAX_ END) AS MAX_C2
FROM temp
GROUP BY customerid;
Output:

To match the 1MB query limit the output could be splitted and materialized in temporary table first like:
CREATE TEMPORARY TABLE t_SUM
AS
SELECT customer_id,
SUM(...)
FROM tab;
CREATE TEMPORARY TABLE t_COUNT
AS
SELECT customer_id,
SUM(...)
FROM tab;
CREATE TEMPORARY TABLE t_MAX
AS
SELECT customer_id,
SUM(...)
FROM tab;
Combined query:
SELECT *
FROM t_SUM AS s
JOIN t_COUNT AS c
ON s.customer_id = c.customer_id
JOIN t_MAX AS m
ON m.customer_id = c.customer_id
-- ...
CodePudding user response:
you cannot ask 54k sets of three column3 in a query, because:
the 50,000th set looks like (if precomputed into tables like Lukasz suggests)
s.s_50000 as sum_50000,
c.c_50000 as count_50000,
m.m_50000 as max_50000,
is 75 bytes, and 54K * 75 = 4,050,000 so even asking for 54K columns (you are have 18K sets of 3 columns) would 1.3MB so too larger.
Which means you have to build your temp tables, as suggested by Lukasz, you would have to use:
select s.customer_id, s.*, c.*, m.*
from sums as s
join counts as c on s.customer_id = c.customer_id
join maxs c on m.customer_id = c.customer_id
but building those temp tables has 18K columns of
SUM(IFF(FILTER_='c18000',SUM_,null)) AS SUM_18000
is 50 bytes, thus 18K of those lines takes 90K, so that might work.
But you then have problems like this person with their 8K columns started having prbolems:
which is to all say, this thing you are doing seems of very low value, what system is going to make sense of 50K columns of data that can not handling processing many rows. It just feels like a, Tool A we know how to do Z and not Y, so Tool B must produce answers in Z format verse the natural concepts of Y..