I am working on sign language detection using VGG16 pre-trained model with grayscale images. When I am trying to run the model.fit command, I am getting the following error.
CLARIFICATION
I already have images as RGB form but I want to use them as grayscale to check if they would work with grayscale. The reason being, with color images, I am not getting the accuracy which I am expecting. It is having test accuracy of max 40% only and getting overfitted on dataset.
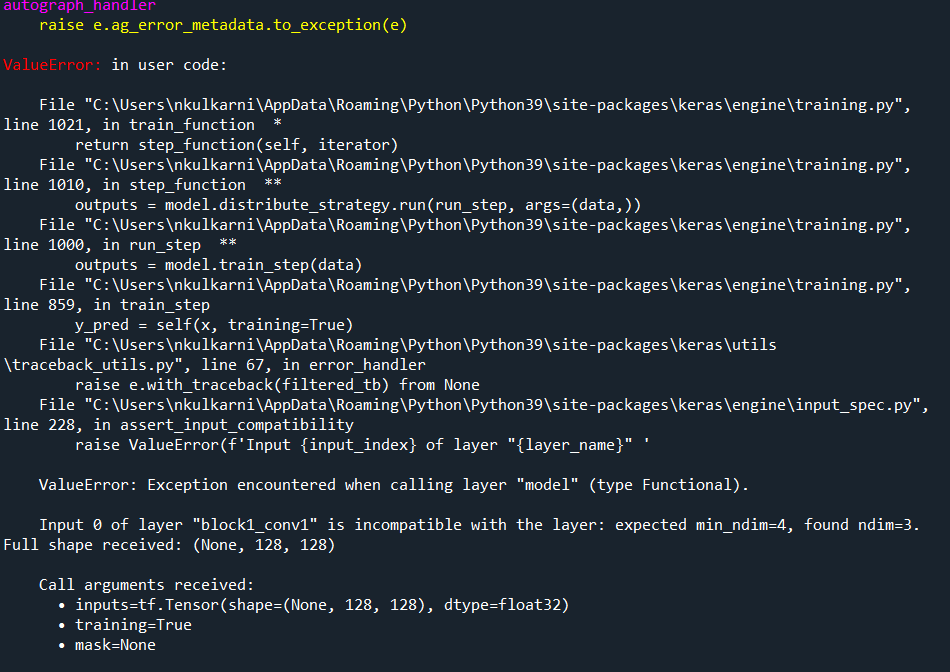
Also, this is my model command
vgg = VGG16(input_shape= [128, 128] [3], weights='imagenet', include_top=False)
This is my model.fit command
history = model.fit(
train_x,
train_y,
epochs=15,
validation_data=(test_x, test_y),
callbacks=[early_stop, checkpoint],
batch_size=32,shuffle=True)
I am new to working with pre-trained models. When I am trying to run the code with color images with 3 channels, my model is getting into overfitting and val_accuracy doesn't rise above 40% so I want to give try the grayscale images as I have added many data augmentation techniques but accuracy is not improving. Any leads are welcomed as I am stuck into this for long time now.
CodePudding user response:
The simplest (and likely fastest) solution I can think of is to just convert your image to rgb. You can do this as part of your model.
model = Sequential([
tf.keras.layers.Lambda(tf.image.grayscale_to_rgb),
vgg
])
This will fix your issue with VGG. I also see that you're missing the last dimensionality for your images. Images in grayscale are expected to be of shape [height, width, 1], but you simply have [height, width]. You can fix this using tf.expand_dims:
model = Sequential([
tf.keras.layers.Lambda(
lambda x: tf.image.grayscale_to_rgb(tf.expand_dims(x, -1))
),
vgg,
])
Note that this solution solves the problem in the graph, so it runs online. Meaning, at runtime, you can feed data exactly the same way you have it now (in the shape [128, 128], without a channels dimension) and it will still functionally work. If this is your expected dimensionality during runtime, this will be faster than manipulating your data before throwing it into the model.
By the way, none of this is ideal, given that VGG was trained specifically to work best with color images. Just thought I should add that.
CodePudding user response:
Why are you getting overfitting?
Maybe for different reasons:
- Your images and labels don't equally exist in the train, Val, test. (maybe you have images in train and don't have them in test.) Or your train, Val, test data don't stratify correctly and you train your model on a specific area in your data and features.
- You Dataset is very small and you need more data.
- Maybe you have noise in your datase, first make sure to remove noise from the dataset. (if you have noise, model fit on your noise.)
How can you input grayscale images to VGG16?
For Using VGG16, you need to input 3 channels images. For this reason, you need to concatenate your images like below to get three channels images from grayscale:
image = tf.concat([image, image, image], -1)
Example of training VGG16 on grayscale images from fashion_mnist dataset:
from tensorflow.keras.applications.vgg16 import VGG16
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
train, val, test = tfds.load(
'fashion_mnist',
shuffle_files=True,
as_supervised=True,
split = ['train[:85%]', 'train[85%:]', 'test']
)
def resize_preprocess(image, label):
image = tf.image.resize(image, (32, 32))
image = tf.concat([image, image, image], -1)
image = tf.keras.applications.densenet.preprocess_input(image)
return image, label
train = train.map(resize_preprocess, num_parallel_calls=tf.data.AUTOTUNE)
test = test.map(resize_preprocess, num_parallel_calls=tf.data.AUTOTUNE)
val = val.map(resize_preprocess, num_parallel_calls=tf.data.AUTOTUNE)
train = train.repeat(15).batch(64).prefetch(tf.data.AUTOTUNE)
test = test.batch(64).prefetch(tf.data.AUTOTUNE)
val = val.batch(64).prefetch(tf.data.AUTOTUNE)
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(32,32,3))
base_model.trainable = False ## Not trainable weights
model = tf.keras.Sequential()
model.add(base_model)
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=.4))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=.4))
model.add(tf.keras.layers.Dense(10, activation='sigmoid'))
model.compile(loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
optimizer='Adam',
metrics=['accuracy'])
model.summary()
fit_callbacks = [tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy', patience = 4, restore_best_weights = True)]
history = model.fit(train, steps_per_epoch=150, epochs=5, batch_size=64, validation_data=val, callbacks=fit_callbacks)
model.evaluate(test)
Output:
Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 1, 1, 512) 14714688
flatten_3 (Flatten) (None, 512) 0
dense_9 (Dense) (None, 1024) 525312
dropout_6 (Dropout) (None, 1024) 0
dense_10 (Dense) (None, 256) 262400
dropout_7 (Dropout) (None, 256) 0
dense_11 (Dense) (None, 10) 2570
=================================================================
Total params: 15,504,970
Trainable params: 790,282
Non-trainable params: 14,714,688
_________________________________________________________________
Epoch 1/5
150/150 [==============================] - 6s 35ms/step - loss: 0.8056 - accuracy: 0.7217 - val_loss: 0.5433 - val_accuracy: 0.7967
Epoch 2/5
150/150 [==============================] - 4s 26ms/step - loss: 0.5560 - accuracy: 0.7965 - val_loss: 0.4772 - val_accuracy: 0.8224
Epoch 3/5
150/150 [==============================] - 4s 26ms/step - loss: 0.5287 - accuracy: 0.8080 - val_loss: 0.4698 - val_accuracy: 0.8234
Epoch 4/5
150/150 [==============================] - 5s 32ms/step - loss: 0.5012 - accuracy: 0.8149 - val_loss: 0.4334 - val_accuracy: 0.8329
Epoch 5/5
150/150 [==============================] - 4s 25ms/step - loss: 0.4791 - accuracy: 0.8315 - val_loss: 0.4312 - val_accuracy: 0.8398
157/157 [==============================] - 2s 15ms/step - loss: 0.4457 - accuracy: 0.8325
[0.44566288590431213, 0.8324999809265137]