I am trying to upload a dataframe to bigquery which contains a column that is a list of users.
A typical value in the column would be ['USER1', 'USER2', 'USER3'].
No matter how much I try though when trying to specify the BQ schema, I am never able to manage to get it to understand it is an array of strings.
Here is an example of what I tried for some reference.
bq_schema = [
bigquery.SchemaField("reply_users", field_type='RECORD', fields=[bigquery.SchemaField("user", "STRING", mode="REPEATED")]),
]
I've tried and tried but I just cannot work out how to do this.
Any advice greatly appreciated.
CodePudding user response:
With that schema, your dataframe should look like this. See code below:
from google.cloud import bigquery
import pandas as pd
client = bigquery.Client()
table_id = "project_id.sandbox.nested_from_df"
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("reply_users", field_type='RECORD', fields=[bigquery.SchemaField("user", "STRING", mode="REPEATED")]),
],
)
data = {"reply_users": [{ "user": ["user1","user2"]}]}
df = pd.DataFrame(data)
print(df)
job = client.load_table_from_dataframe(df, table_id, job_config=job_config)
job.result()
Output (dataframe):

Loaded data:
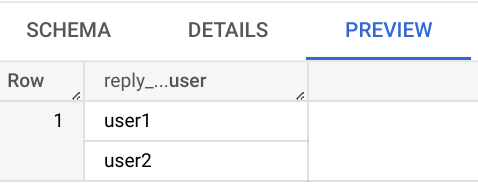
CodePudding user response:
Thanks a lot.
I've had another dig through this in the morning and see where I went wrong.
My data is in the format:
data = {"reply_users": ["user1","user2"]}
Given this, the correct format for the schema is :
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("reply_users", field_type='STR', mode='REPEATED')
My issue was that some other function had converted the list in python into a string without me realising so this was just chopping up the string letter by letter.
Appreciate the help though, finally understand how this works !