I have a dataframe for a csv, and a datafrom for a row from database.
csv_df
Id Location Name
0 y y
1 n y
2 y n
rule_df
Location Name
y n
I want to filter the csv_df based on the rule_df, so that the result is two result sets, one where all columns match those in the rule_df, the other data set where any one column doesn't match any one column in the rule_df.
Expected Result
Rows matched
Both Location and Name match to those in rule_df
Id Location Name
2 y n
Rows don't match
Id Location Name
0 y y
1 n y
The code below works partially, but cannot get the expected result:
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['y', 'n', 'y'],
'Name':['y','n','n']})
rule_df = pd.DataFrame({'Location': ['y'], 'Name':['n']})
print('csv_df', csv_df)
print('rule_df', rule_df)
for col in rule_df.columns:
print(rule_df[col].name, rule_df[col].values[0])
criterion = csv_df[rule_df[col].name].map(lambda x: x.startswith(rule_df[col].values[0]))
print('rs:',csv_df[criterion])
Not Expected Result
rs: Id Location Name
1 1 n n
2 2 y n
Update
Sorry for the confusion and not specifying clearly.
Please see below the added requirements and changes.
1.Both cvs_df and rule_df contain more than two columns, e.g. 10-30 columns. The solution should be able to handle more than two columns in both xx_df.
2 Both cvs_df and rule_df contain data like below:
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['', 'LD', ''],
'Name':['Tom','','']})
rule_df = pd.DataFrame({'LocationRequired': ['y'], 'NameRequired':['n']})
Expected Result
Rows matched
Both Location and Name match to those in rule_df
Id Location Name
1 LD
Rows don't match
Id Location Name
0 Tom
2
Update 2
Sorry again for the confusion and not specifying clearly.
Please see below the added requirements and changes.
1.The cvs_df contains more than two columns, e.g. 10-30 columns. This is the same as the Update above.
2 The rule_df contains more than one row. This is the new and only change from above.
2 Both rule_df and rule_df contain data like below:
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['', 'LD', ''],
'Name':['Tom','','']})
rule_df = pd.DataFrame([['location','y'],
['name','n']],
columns= ['ColName','Required'])
rule_df
ColName Required
0 location y
1 name n
The expected result is the same as Update above.
CodePudding user response:
Error is your example csv_df dataframe in end is different from your csv_df dataframe mentioned in very starting.
# It is not aligned with your example in starting
# Name - y, n, n
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['y', 'n', 'y'],
'Name':['y','n','n']})
It should be -> Name - y,y,n
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['y', 'n', 'y'],
'Name':['y','y','n']})
Below code gives required output using JOINS
csv_df = pd.DataFrame({ 'Id':['0','1','2'],
'Location': ['y', 'n', 'y'],
'Name':['y','y','n']})
rule_df = pd.DataFrame({'Location': ['y'], 'Name':['n']})
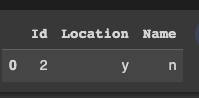
pd.merge(csv_df, rule_df, left_on=['Location','Name'], right_on=['Location','Name'],how='inner' )
First Output :
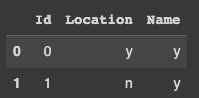
Second Output:
pd.merge(csv_df, rule_df, left_on=['Location','Name'], right_on=['Location','Name'], how='left',indicator=True ).\
query("_merge == 'left_only'").drop('_merge', axis=1)
CodePudding user response:
Build a mask, then slice:
mask = csv_df[rule_df.columns].eq(rule_df.squeeze(), axis=1).all(1)
# [False, False, True]
df_match = csv_df[mask]
df_diff = csv_df[~mask]
output:
# df_match
Id Location Name
2 2 y n
# df_diff
Id Location Name
0 0 y y
1 1 n n
update
If the rules dataframe define the columns that should not contain null/empty data, define the mask with:
m = rule_df.squeeze().eq('y')
mask = csv_df.add_suffix('Required')[m[m].index].fillna('').ne('').all(1)
Then, as above:
df_match = csv_df[mask]
df_diff = csv_df[~mask]
CodePudding user response:
Edit (Different question --> different answer).
It looks like we have rule_df containing a single row and prescribing, for each column, whether that column must be non-empty ( != ''). First, we transform this into a bool Series where names correspond to what they are in the data df (i.e., removing the 'Required' suffix):
r = (rule_df.set_axis(rule_df.columns.str.replace(r'Required$', '', regex=True),
axis=1) == 'y').squeeze()
>>> r
Location True
Name False
Name: 0, dtype: bool
Then, we turn our attention to csv_df and flag where the values are empty:
>>> csv_df[r.index] != ''
Location Name
0 False True
1 True False
2 False False
Now, the desired logic (if I understand correctly) is that we want to find rows that have none of the "required" columns empty:
ix = ((csv_df[r.index] != '') | ~r).all(axis=1)
>>> ix
0 False
1 True
2 False
dtype: bool
Or, more simply:
ix = csv_df[r[r].index].all(axis=1)
Then:
matching = csv_df.loc[ix]
no_match = csv_df.loc[~ix]
>>> matching
Id Location Name
1 1 LD
>>> no_match
Id Location Name
0 0 Tom
2 2