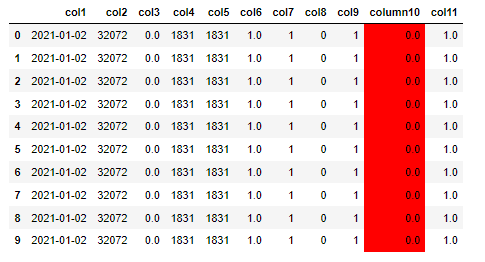
I would like to color a column in my dataframe (using the method proposed in a given answer, link below). So (taking only 1st row of my dataframe) I used to change the color the following code expression:
data1.head(1).style.set_properties(**{'background-color': 'red'}, subset=['column10'])
However it causes another problem: it changes the format of my dataframe (= addes more 0's after decimal point..). Is there any possibility I can keep the old format of my dataframe and still be able to color a column? Thanks in advance
Old output (first row):
2021-01-02 32072 0.0 1831 1831 1.0 1 0 1 0.0 1.0
New output (first row):
2021-01-02 32072 0.000000 1831 1831 1.000000 1 0 1 0.000000 1.000000 1.000000
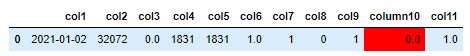
Once you use style, it is no longer a pandas dataframe and is now a Styler object. So, normal commands that work on pandas dataframes no longer work on your newly styled dataframe (e.g. just doing head(10) no longer works). But, there are work arounds. If you want to look at only the first 10 rows of your Styler after you applied the style, you can export the style that was used and then reapply it to just look at the top 10 rows:
data = [{"col1":"2021-01-02", "col2":32072, "col3":0.0, "col4":1831, "col5":1831,
"col6":1.0, "col7":1, "col8":0, "col9":1, "column10":0.0, "col11":1.0}]
data1 = pd.DataFrame(data)
data1 = data1.append(data*20).reset_index(drop=True)
data1 = data1.style.format(precision=1, subset=list(data1.columns)).set_properties(**{'background-color': 'red'}, subset=['column10'])
Gives a large dataframe:
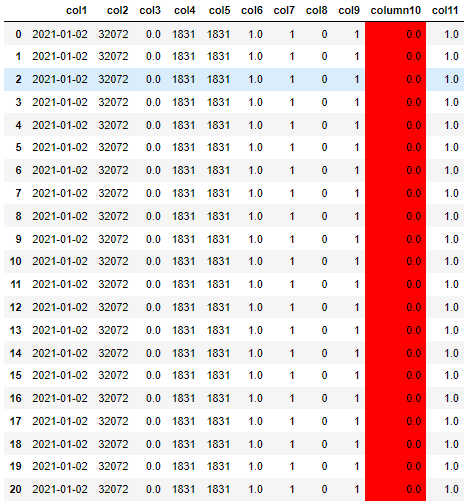
And then using this code afterwards will head (ie show) only 10 of the rows:
style = data1.export()
data1.data.head(10).style.use(style).format(precision=1, subset=list(data1.columns))
Now it is only showing the first 10 rows: