I have a dataframe - record of the stimulation
There i have a column where laser impulses are marked by '1's And a column where the ECG peaks marked by '1's
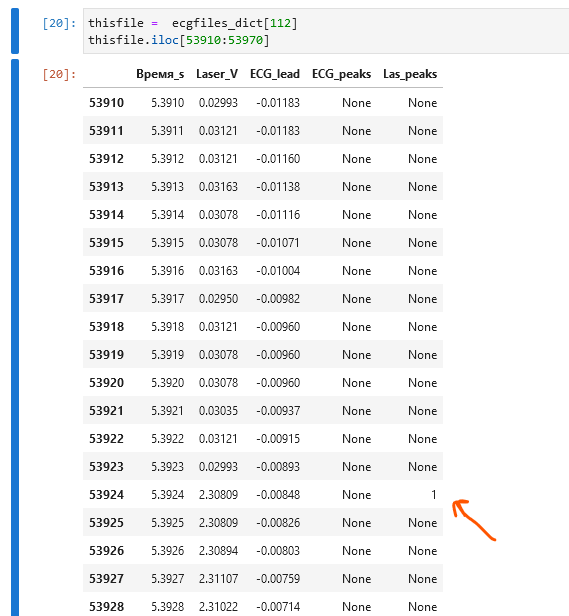
I am trying to come up with an efficient method to find two ecg peaks closest to the laser peak - one before and one after the laser peak
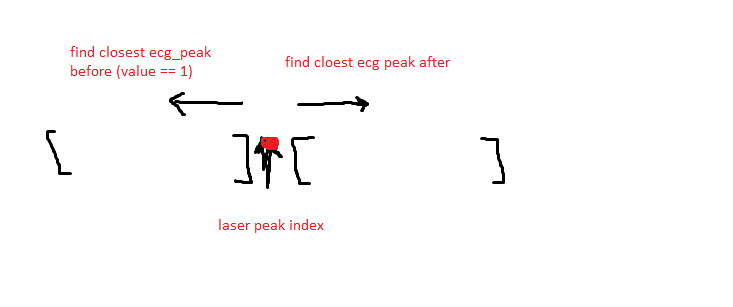
For me the simplest way seems to be a 'while' cycle, but maybe there are some pandas functions that can make it more efficiently?
CodePudding user response:
Lets say you have the below dataframe to demonstrate:
df = pd.DataFrame({
'ECG_peaks':[None, None, None, None, None, 1, None, None, None, 1, None, None, None, None, 1, None, None, None],
'Las_peaks':[None, None, None, None, None, None, None, 1, None, None, None, None, 1, None, None, None, None, None]
})
print(df):
ECG_peaks Las_peaks
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 1.0 NaN
6 NaN NaN
7 NaN 1.0
8 NaN NaN
9 1.0 NaN
10 NaN NaN
11 NaN NaN
12 NaN 1.0
13 NaN NaN
14 1.0 NaN
15 NaN NaN
16 NaN NaN
17 NaN NaN
Now get the indexes of Las_peaks where value is 1 as :
las_peaks = df.loc[df.Las_peaks==1].index
Similarly for ecg_peaks:
ecg_peaks = df.loc[df.ECG_peaks==1].index
Now I use np.searchsorted to get the nearest index where each laser peak index can be inserted in ecg peak indexes.
searches = [np.searchsorted(ecg_peaks, idx) for idx in las_peaks]
Then the result of the ecg indexes with one nearest before and one nearest after can be found as:
[(ecg_peaks[max(s-1, 0)], ecg_peaks[s]) for s in searches]
For this example input, the output is :
[(5, 9), (9, 14)]
where 5 is the nearest-before index for laser peak at 7 and 9 is the nearest-after index for laser peak at 7.
Similarly 9, 14 for 12th laser index.
CodePudding user response:
Here is an option using pd.IntervalIndex() and get_indexer()
ecg = df['ECG_peaks'].dropna().index
las = df['Las_peaks'].dropna().index
idx = pd.IntervalIndex.from_tuples(([(ecg[i],ecg[i 1]) for i in range(len(ecg)-1)]))
list(idx[idx.get_indexer(las)].to_tuples())