Input :
B 0 15000.000000 698.617126 -0.745298
B 1 17000.000000 647.001708 -0.269421
B 2 18000.000000 649.572265 -0.097540
B 4 19000.000000 665.282775 0.008724
B 5 20000.000000 690.836975 -0.011101
I have a data frame with 5 columns, in the 1st column, there is a jump in the 3rd row, instead of the value 3 it is 4 and in column 2 there is a jump in the 1st row, instead of 16000 it is 17000. How to mark these values. Also, how find this jump with a specified value in each column?
Expected output:
considering 1st column. display the index number when the difference from 1 row to the next row is not 1. example: in the 1st column above, the difference of the value of 1st and 2nd row is 2 instead of 1.
output:
0 nan nan nan nan
1 1 2000 -51.61 0.47628
2 2 1000 2.57 0.171881
CodePudding user response:
In my opinion, the code is heavily dependent on the definition of what jumps are. Let's say it's an absolute difference between vertical neighbors that is greater than 75% of others. In addition, why not mark the areas with stagnation - those which are lower then 25% of others?
In this case the code could be like below:
import pandas as pd
import numpy as np
from io import StringIO
data = '''
0 15000.000000 698.617126 -0.745298
1 17000.000000 647.001708 -0.269421
2 18000.000000 649.572265 -0.097540
4 19000.000000 665.282775 0.008724
5 20000.000000 690.836975 -0.011101
'''
df = pd.read_csv(
StringIO(data),
sep='\s ',
header=None,
names=['one','two','three','four']
)
# find an absolute difference between vertical neighbours
# and fill the first line with zero as if no difference detected
diff = df.diff().abs().fillna(df.diff().median()) # concide DataFrame.pct_change as an option
# define a significant difference as one
# that is less then 25th or greater than the 75th percentile
low, high = np.percentile(diff, [25, 75], axis=0)
jump = diff > high
stagnation = diff < low
# color significant difference in green and red
# for the 25 and 75 percentiles, respectively
# notice that .apply iterates over the columns
# and jump/stagnation masks have the same captions as df
(
df.style
.hide_index()
.format({'one':'{:g}','two':'{:g}','three':'{:.2f}','four':'{:.2f}'})
.apply(lambda x:
np.where(
jump[x.name],
'color: red',
None
)
).apply(lambda x:
np.where(
stagnation[x.name],
'color: green',
None
)
)
)
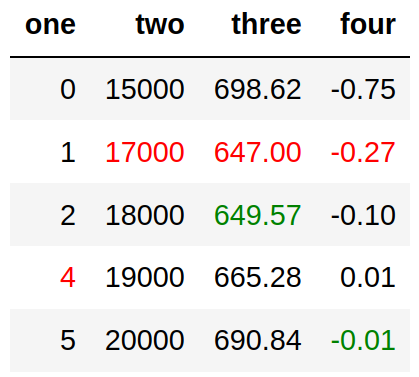
Output:
CodePudding user response:
Given df:
col_0 col_1 col_2 col_3 col_4
0 B 0 15000.0 698.617126 -0.745298
1 B 1 17000.0 647.001708 -0.269421
2 B 2 18000.0 649.572265 -0.097540
3 B 4 19000.0 665.282775 0.008724
4 B 5 20000.0 690.836975 -0.011101
We can mark where the difference is greater than 1 or 1000 like so:
df['jump_1'] = df['col_1'].diff().gt(1)
df['jump_2'] = df['col_2'].diff().gt(1000)
# If you want to mark the row above, change to look like:
# df['col_1'].diff(-1).abs().gt(1)
# Output:
col_0 col_1 col_2 col_3 col_4 jump_1 jump_2
0 B 0 15000.0 698.617126 -0.745298 False False
1 B 1 17000.0 647.001708 -0.269421 False True
2 B 2 18000.0 649.572265 -0.097540 False False
3 B 4 19000.0 665.282775 0.008724 True False
4 B 5 20000.0 690.836975 -0.011101 False False
If we just want the row where True:
>>> df[df['jump_1']]
col_0 col_1 col_2 col_3 col_4 jump_1 jump_2
3 B 4 19000.0 665.282775 0.008724 True False
If we just want the indices in a list:
>>> df[df['jump_1']].index.to_list()
[3]