I was looking to group coefficient from a single model in a dot and whisker plot:
Here is a sample:
## Simulate data
set.seed(42)
n <- 1e3
d <- data.frame(
# Covariates
projects_0_300_minus2 = rnorm(n),
projects_0_300_minus1 = rnorm(n),
projects_0_300_0 = rnorm(n),
projects_0_300_1 = rnorm(n),
projects_0_300_2 = rnorm(n),
projects_300_600_minus2 = rnorm(n),
projects_300_600_minus1 = rnorm(n),
projects_300_600_0 = rnorm(n),
projects_300_600_1 = rnorm(n),
projects_300_600_2 = rnorm(n),
projects_600_800_minus2 = rnorm(n),
projects_600_800_minus1 = rnorm(n),
projects_600_800_0 = rnorm(n),
projects_600_800_1 = rnorm(n),
projects_600_800_2 = rnorm(n),
# Individuals and firms
id = factor(sample(20, n, replace=TRUE)),
firm = factor(sample(13, n, replace=TRUE)),
# Noise
u = rnorm(n)
)
# Effects for individuals and firms
id.eff <- rnorm(nlevels(d$id))
firm.eff <- rnorm(nlevels(d$firm))
# Left hand side
d$y <- d$projects_0_300_minus2 0.5*d$projects_0_300_minus1 d$projects_0_300_0 0.5*d$projects_0_300_1 d$projects_0_300_2 d$projects_300_600_minus2 d$projects_300_600_minus1 0.5*d$projects_300_600_0 d$projects_300_600_1 0.5*d$projects_300_600_2 0.5*d$projects_600_800_0 d$projects_600_800_minus2 0.5*d$projects_600_800_minus1 d$projects_600_800_0 0.5*d$projects_600_800_1 d$projects_600_800_2 id.eff[d$id] firm.eff[d$firm] d$u
## extract predictor names
d_pred <- subset(d, select = -c(id,firm,u,y))
d_pred_names <- names(d_pred)
## model
Formula <- formula(paste("y ~ ", paste(d_pred_names, collapse=" "),"| id firm | 0 | 0"))
results <- felm(Formula, data = d)
#extract names for grouping of coefficient s
projects_minus2 <- names(d[ , grepl( "00_minus2" , names( d ) ) ])
projects_minus1 <- names(d[ , grepl( '00_minus1' , names( d ) ) ])
projects_0 <- names(d[ , grepl( "00_0" , names( d ) ) ])
projects_1 <- names(d[ , grepl( "00_1" , names( d ) ) ])
projects_2 <- names(d[ , grepl( "00_2" , names( d ) ) ])
## plot individual BUT WANT TO GROUP THESE INTO ONE PLOT
Turnover_projects_minus2 <- jtools::plot_coefs(results, coefs = projects_minus2) labs(title = 'Turnover_projects -2')
Turnover_projects_minus1 <- jtools::plot_coefs(results, coefs = projects_minus1) labs(title = 'Turnover_projects -1')
Turnover_projects_0 <- jtools::plot_coefs(results, coefs = projects_0) labs(title = 'Turnover_projects 0')
Turnover_projects_1 <- jtools::plot_coefs(results, coefs = projects_1) labs(title = 'Turnover_projects 1')
Turnover_projects_2 <- jtools::plot_coefs(results, coefs = projects_2) labs(title = 'Turnover_projects 2')
ggarrange(Turnover_projects_minus2, Turnover_projects_minus1, Turnover_projects_0,Turnover_projects_1,Turnover_projects_2,
ncol = 2, nrow = 5)
Using this image as an example:
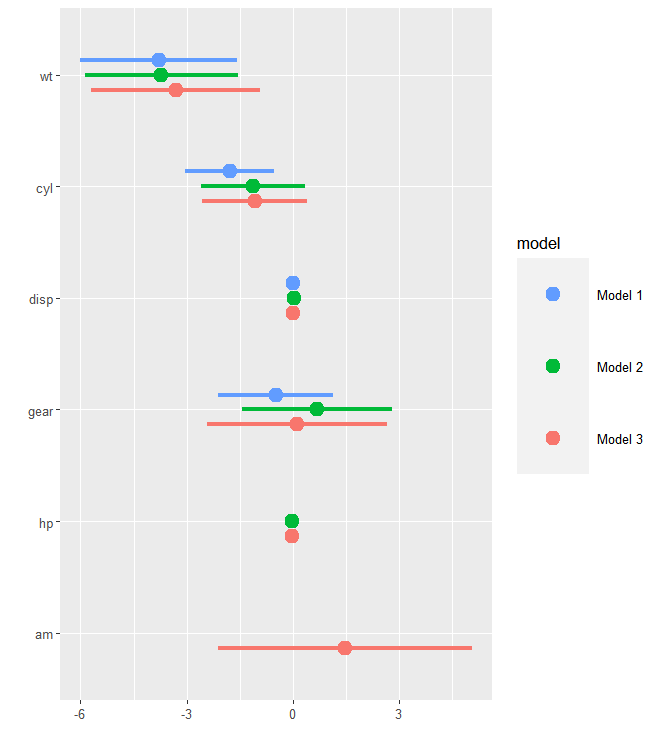
I would like the variables that include seperately: 0-300, 300-600, 600-800, which will be on the Y axis where the above image has 'wt' , 'cyl', 'disp'.
Then, for each one of these, they would grouped by 5 points that include 'minus2', 'minus1' , '0' , '1' , '2' like the above image where 'model1', 'model2', 'model3' are grouped together.
Something like this i think but couldnt get it work..:
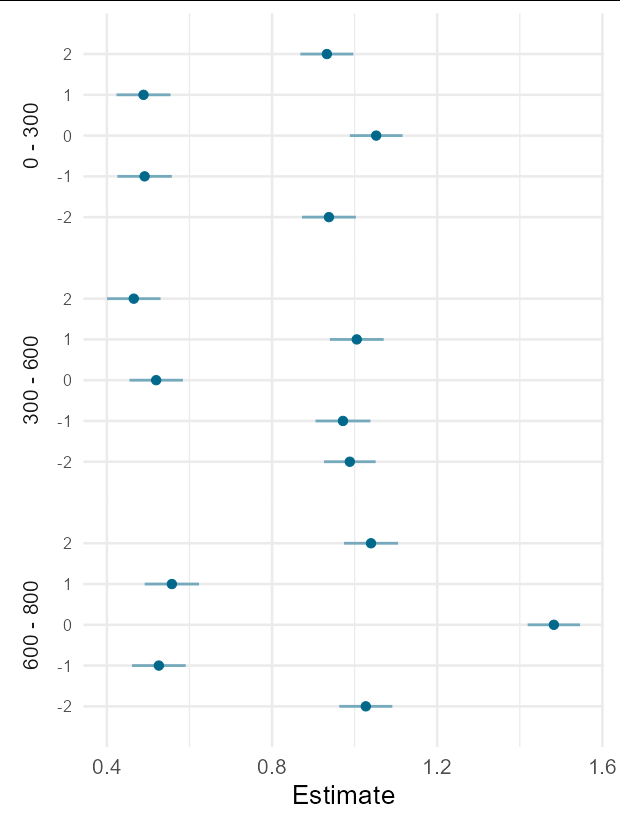
Or
ggplot(plot_df, aes(x = var1, y = Estimate, color = var2))
geom_linerange(aes(ymin = lower, ymax = upper), size = 1,
position = position_dodge(width = 0.5))
geom_point(position = position_dodge(width = 0.5), size = 3)
coord_flip()
labs(x = NULL, color = NULL)
scale_color_brewer(palette = "Set1", labels = seq(-2, 2))
theme_minimal(base_size = 20)
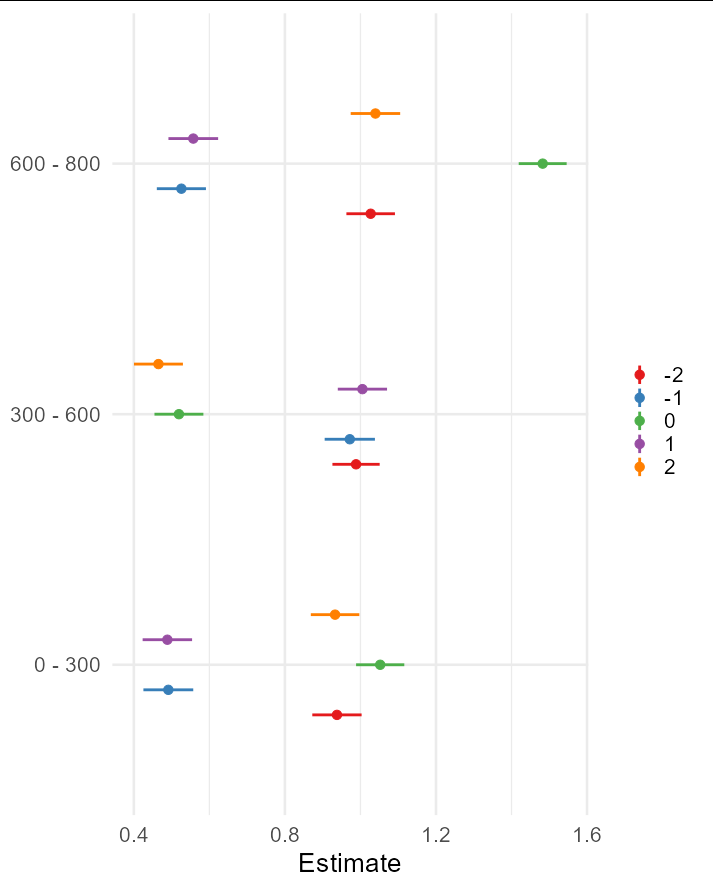
Created on 2022-09-10 with reprex v2.0.2