I have written the code to generate the word and its corresponding frequency of occurrence for task1-input1.txt excluding the stop words in the stopwords.txt
public class TopKCommonWords {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
Set<String> stopwords = new HashSet<String>();
private static final String STOP_WORD_PATH = "C:\\Users\\user\\Desktop\\CS4225\\TopKCommonWords\\input\\stopwords.txt";
@Override
protected void setup(Context context) {
try {
Path path = new Path(STOP_WORD_PATH);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(
fs.open(path)));
String word = null;
while ((word = br.readLine()) != null) {
stopwords.add(word);
}
} catch (IOException e) {
e.printStackTrace();
}
}
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
if (stopwords.contains(word.toString()))
continue;
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum = val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "counter1");
job.setJarByClass(TopKCommonWords.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[3]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
This are my arguments.
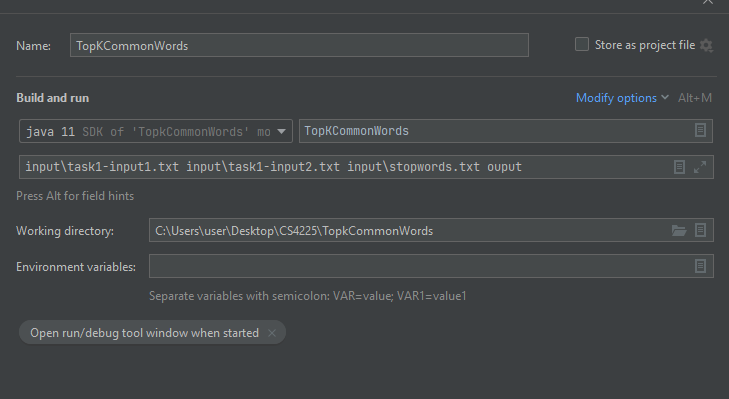
I understand that by changing
FileInputFormat.addInputPath(job, new Path(args[0]));
from 0 to 1, I can get the words and its frequency of occurrence in task1-input2.txt.
For example in my output of occurrences:
task1-input1: task1-input2:
coffee 3 coffee 2
happy 10 good 3
good 6 sweet 5
How can i compare these 2 output and only return the common and the ones with the least frequency? The expected result should be:
coffee 2
good 3
CodePudding user response:
If you wanted to sum words from all files, you don't need to combine output files, instead, you can use addInputPath multiple times to read multiple files using MultipleInputs class
Alternatively, you should be able to pass input folder as an argument to read all files within it.
If you want to find the word with minimum count per file, you'll need a second reducer
You already have output location as a variable
Path output1 = new Path(args[3];
FileOutputFormat.setOutputPath(job, output1));
So create another job that reads that location
But you might be able to use only one job if you use a Combiner to do the word count, and using the filename as your key