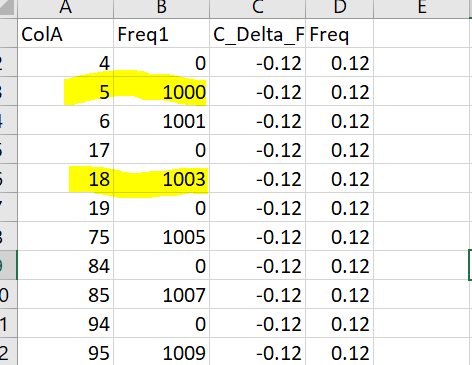
I want to calculate consecutive numbers from colA and then select the middle number from consecutive seqeunce to print out value corresponding to it in column Freq1
this code is not printing any value for col in df.ColA: if col == col 1 and col 1 == col 2: print(col) can anyone suggest any idea
ColA Freq1
4 0
5 100
6 200
18 5
19 600
20 700
CodePudding user response:
This will return the resulting rows you are looking for:
Basically where ColA is equal to the previous row 1 and the next row - 1
This of course operates under the assumption that there are always only 3 consecutive numbers.
df.loc[(df['ColA'].eq(df['ColA'].shift(1).add(1))) & (df['ColA'].eq(df['ColA'].shift(-1).sub(1)))]
CodePudding user response:
You can use a custom groupby to identify the stretches of contiguous values, then size of the groups and the middle value:
# find consecutive values
group = df['ColA'].diff().ne(1).cumsum()
# make grouper
g = df.groupby(group)['ColA']
# get index of row in group
# compare to group size to find mid-point
m = g.cumcount().eq(g.transform('size').floordiv(2))
# perform boolean indexing
out = df.loc[m]
output:
ColA Freq1
1 5 100
4 19 600
intermediates:
ColA Freq1 diff group cumcount size size//2 m
0 4 0 NaN 1 0 3 1 False
1 5 100 1.0 1 1 3 1 True
2 6 200 1.0 1 2 3 1 False
3 18 5 12.0 2 0 3 1 False
4 19 600 1.0 2 1 3 1 True
5 20 700 1.0 2 2 3 1 False