Lets say we have two data frames(df1,df2) like this 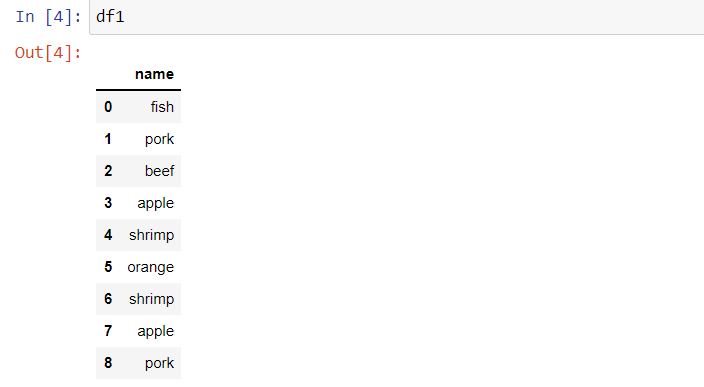
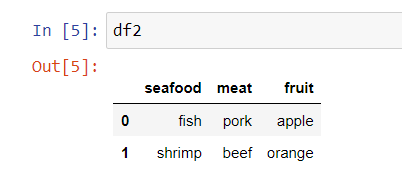
We need to find the values from df1.name that exist in df2(it could be at any column, we need to search the value in df2)
Finally, we create a column df1.category, which represent the category from df2. Like showed below
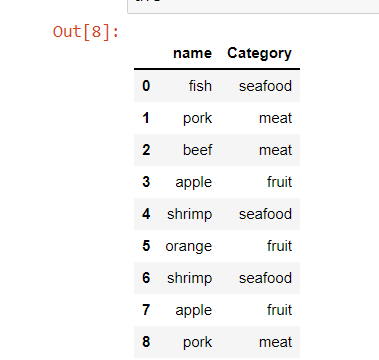
Update: Here is my code for define df1 and df2
df1 = pd.DataFrame({'name': ['fish','pork','beef','apple','shrimp','orange','shrimp','apple','pork']})
df2 =pd.DataFrame( {'seafood': ['fish', 'shrimp'],
'meat' : ['pork','beef'],
'fruit': ['apple','orange']})
After I run this code,
mel = df2.melt(var_name='Category' ,value_name='name')
df1 = df1.merge(mel, on='name')
The index of name is automatically changed, is there any way to keep the original index? Thanks
CodePudding user response:
You can use melt and merge for this.
If you care about the order of the output, you could add how='left' to the merge function.
import pandas as pd
df1 = pd.DataFrame({'name':['fish','pork','beef','apple','shrimp','orange','shrimp','apple','pork']})
df2 = pd.DataFrame({'seafood':['fish','shrimp'], 'meat':['pork','beef'], 'fruit':['apple','orange']})
output = df1.merge(df2.melt(var_name='Category', value_name='name'), on='name')
print(output)
Output
name Category
0 fish seafood
1 pork meat
2 pork meat
3 beef meat
4 apple fruit
5 apple fruit
6 shrimp seafood
7 shrimp seafood
8 orange fruit
CodePudding user response:
Another way you can do with apply-lambda.. with if condition... But chris's way is better one...
df1 = pd.DataFrame({"name":["fish","pork","apple"]})
df2 = pd.DataFrame({"seafood":["fish"],
"meat":["pork"],
"fruit":["apple"]})
df1["category"] = df1["name"].apply(lambda x: "seafood" if x in list(df2["seafood"]) else
("meat" if x in list(df2["meat"]) else
("fruit" if x in list(df2["fruit"]) else np.nan)))
Output of df1;
name category
0 fish seafood
1 pork meat
2 apple fruit
CodePudding user response:
I would do the good old for:
for i in df1.index:
for c in df2.columns:
if df1.at[i,'name'] in df2[c].values:
df1.at[i,'category']=c
break