I'm building a word-game in React that, previously, would send user-made words to an online dictionary API as a fetch request, in order to validate the words. However, the servers for the API have been down recently and I no longer want to rely on a third-party in order for my game to work. I had the idea previously to implement a local dictionary in hopes that it would make my game run more smoothly, thanks to cutting out the fetch wait time (however small). After implementing the local dictionary, though, I've noticed that lookup times are a bit longer.
The dictionary file is a massive JSON object (370,000 lines) that I am importing into my main component like so: import * as data from '../../dictionary/words_dictionary.json';
The JSON is structured like this:
"afterwash": 1,
"afterwhile": 1,
"afterwisdom": 1,
"afterwise": 1,
"afterwit": 1,
"afterwitted": 1,
"afterword": 1,
"afterwork": 1,
In order to validate a word that a user has submitted, I am merely checking if the word exists in the keys of my JSON file, as such:
if (Object.keys(data).includes(orderedInput.toLowerCase())) {
dispatch(actions)
else {
dispatch(other actions)
}
I realize of course that my implementation is a horribly slow and inefficient one, however, I have little experience in search optimization. If there is an easy, better way to accomplish this, I would appreciate any pointers in the right direction.
CodePudding user response:
Just index the object, includes is a brute force search.
if (data[orderedInput.toLowerCase()]) {
dispatch(actions)
else {
dispatch(other actions)
}
I would personally use a Set for this, probably no difference in lookup performance but I think slightly better on memory, no need for the 1's.
export const data = new Set([
"afterwash",
"afterwhile",
"afterwisdom",
"afterwise",
...
]);
if (data.has(orderedInput.toLowerCase())) {
dispatch(actions)
else {
dispatch(other actions)
}
CodePudding user response:
First of all, by calling Object.keys you would have to re-access the entire list of words, which would add to the amount of time. If you could instead transform your JSON file to an array (arrays are valid as the root of a JSON object) it would eliminate that call. You can transform the data with a simple Node script you manually run, so you don't have to call it every time a user types:
const fs = require("fs");
const file = fs.readFileSync("path/to/words_dictionary.json");
fs.writeFileSync("path/to/words_dictionary.json", Object.keys(file));
You just have to run that once, then you can remove the object and you eliminate the entire Object.keys call.
Secondly, and perhaps more importantly, you can use the 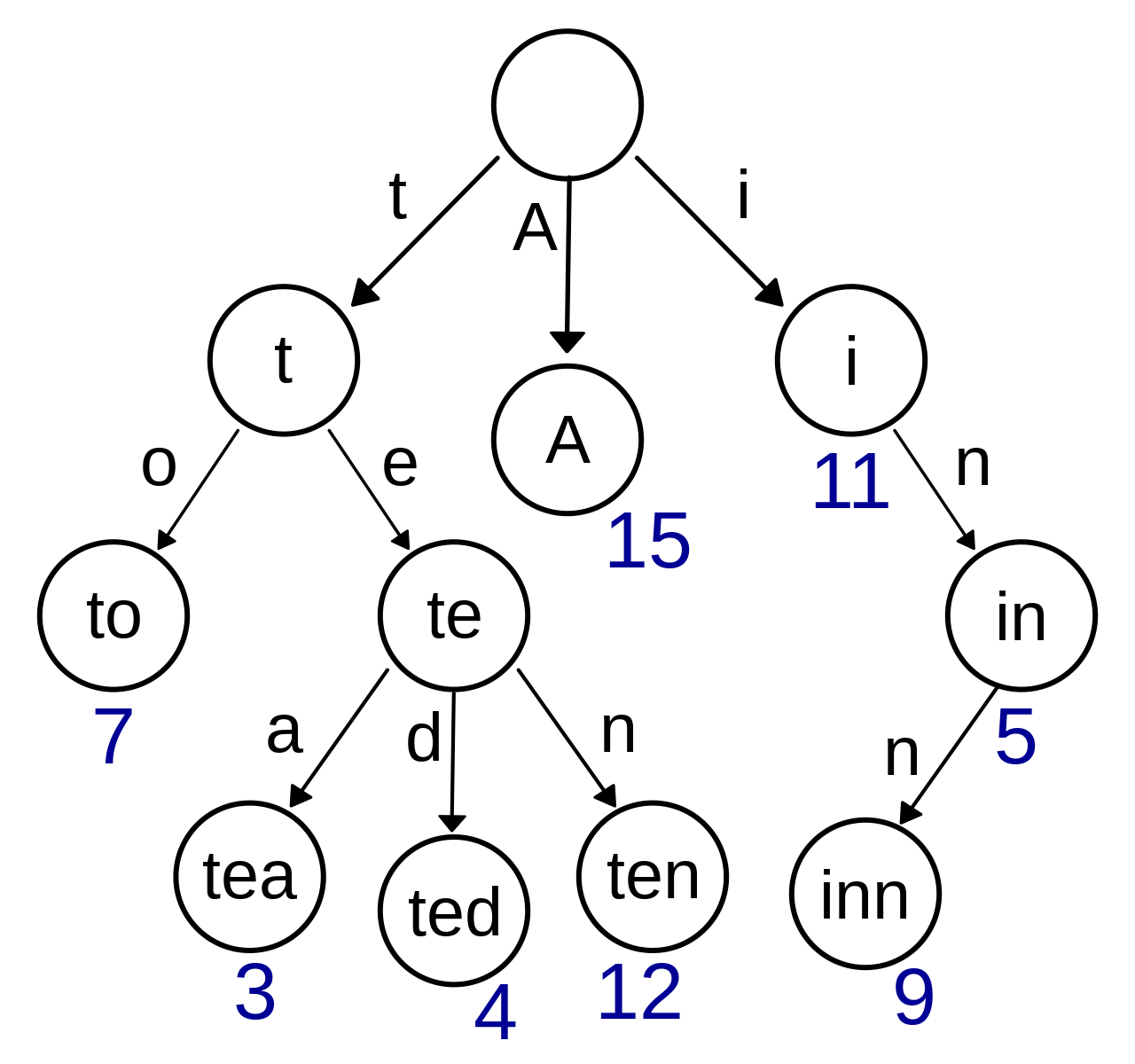 trie illustration | By Booyabazooka (from wikipedia)
trie illustration | By Booyabazooka (from wikipedia)
Here's my sample implementation:
// create a custom trie implementation
class Trie {
constructor(data) {
this.root = {}; // use an object to represent the tree
this.end = Symbol("trieEnd"); // use a symbol to represent the end of a word
// convert each letter into a key
for(const i of data) {
i.split("").reduce((ref, letter, index) => {
ref[letter] = {...(ref[letter] || {})};
if(index === i.length - 1) {
ref[letter][this.end] = 1; // mark this is as the end of a word
}
return ref[letter];
}, this.root);
}
}
search(word) {
let pos = this.root;
for(let i in word) {
pos = pos[word[i]];
if(typeof pos === "undefined")
return false;
if(i == word.length - 1) {
// test if this end is an actual end
if(!Object.hasOwn(pos, this.end))
return false;
}
}
return true;
}
}
const t = new Trie(["hello", "hell", "hi", "boy"]);
console.log(
t.search("hello"),
t.search("boy"),
t.search("ho"),
t.search("not in here"),
t.search("h")
);Benchmarks
Just to prove that trie is much faster (a half-million wordlist is generated, and 100000 random words inside the wordlist are chosen to be found):
// set up
Array.prototype.random = function() {
return this[(Math.random() * this.length) | 0];
}
const alphabet = "abcdefghijklmnopqrstuvwxyz".split("");
const fakeDataList = Array.from({ length: 500000 }, (_, i) => {
const wordLength = ((Math.random() * 20) | 0) 1;
let word = "";
for(let i = 0; i < wordLength; i )
word = alphabet.random();
return word;
});
class Trie {
constructor(data) {
this.root = {};
this.end = Symbol("trieEnd");
for(const i of data) {
i.split("").reduce((ref, letter, index) => {
ref[letter] = {...(ref[letter] || {})};
if(index === i.length - 1) {
ref[letter][this.end] = 1;
}
return ref[letter];
}, this.root);
}
}
search(word) {
let pos = this.root;
for(let i in word) {
pos = pos[word[i]];
if(typeof pos === "undefined")
return false;
if(i == word.length - 1) {
if(!Object.hasOwn(pos, this.end))
return false;
}
}
return true;
}
}
function trieSearch(word, trie) {
return trie.search(word);
}
function naiveSearch(word, list) {
return list.includes(word);
}
const findList = [];
for(let i = 0; i < 100000; i )
findList.push(fakeDataList.random());
function runManyTimes(fn, data) {
for(const w of findList) {
fn(w, data);
}
}
console.time("naive search");
runManyTimes(naiveSearch, fakeDataList);
console.timeEnd("naive search");
console.time("trie initialization");
const t = new Trie(fakeDataList);
console.timeEnd("trie initialization");
console.time("trie search");
runManyTimes(trieSearch, t);
console.timeEnd("trie search");Sure, the initialization takes a while (keep in mind the trie only needs to be initialized once on page load, not on each search), but after that each search is about 16x faster. Quite an improvement to me.
For me, the naive search took ~8s, trie initialization took ~4s, and trie search took ~0.5s.