Can someone help me with the for loop inside for loop (pdfname)?
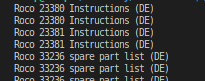
The output should be: Roco 23380 Instructions (DE), Roco 23380 (DE), ...
I have this output now:
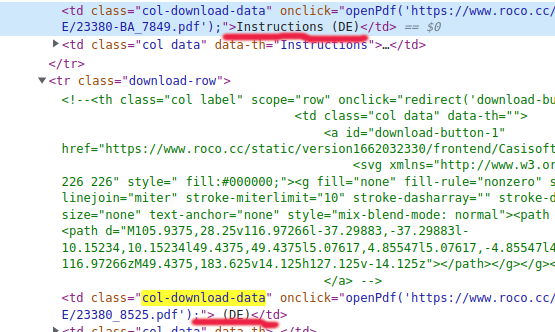
This is source:
This is my code:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import xlsxwriter
import re
import os
productlinks = []
for x in range(1, 2):
r = requests.get(
f'https://www.roco.cc/ren/products/locomotives/steam-locomotives.html?p={x}&verfuegbarkeit_status=41,42,43,45,44')
soup = BeautifulSoup(r.content, 'lxml')
productlist = soup.find_all('li', class_='item product product-item')
for item in productlist:
for link in item.find_all('a', class_='product-item-link', href=True):
productlinks.append(link['href'])
pdflist = []
for url in productlinks:
r = requests.get(url, allow_redirects=False)
soup = BeautifulSoup(r.content, 'html.parser')
for tag in soup.find_all('a'):
on_click = tag.get('onclick')
if on_click:
pdf = re.findall(r"'([^']*)'", on_click)[0]
if 'pdf' in pdf:
name = 'Roco'
try:
reference = soup.find(
'span', class_='product-head-artNr').get_text().strip()
except Exception as e:
print(e)
try:
pdfname = soup.find('td', class_='col-download-data').get_text().strip()
except Exception as e:
print(e)
print(name, reference, pdfname)
CodePudding user response:
You can use findAll instead of find to get all names and then use a variable to keep track of which pdfname should be used.
for url in productlinks:
r = requests.get(url, allow_redirects=False)
soup = BeautifulSoup(r.content, 'html.parser')
# set variable to 0
num_of_pdfs = 0
for tag in soup.find_all('a'):
on_click = tag.get('onclick')
if on_click:
pdf = re.findall(r"'([^']*)'", on_click)[0]
if 'pdf' in pdf:
name = 'Roco'
try:
reference = soup.find(
'span', class_='product-head-artNr').get_text().strip()
except Exception as e:
print(e)
try:
# use find all and use the current pdf as index
pdfname = soup.findAll('td', class_='col-download-data')[num_of_pdfs].get_text().strip()
# increment num_of_pdfs to get the next name on next iteration
num_of_pdfs = 1
except Exception as e:
print(e)
print(name, reference, pdfname)
CodePudding user response:
Replace this
try:
pdfname = soup.find('td', class_='col-download-data').get_text().strip()
except Exception as e:
print(e)
with this:
try:
pdfname = ""
for tag in soup.find_all('td', class_='col-download-data'):
pdfname = pdfname "," tag.get_text().strip()
except Exception as e:
print(e)