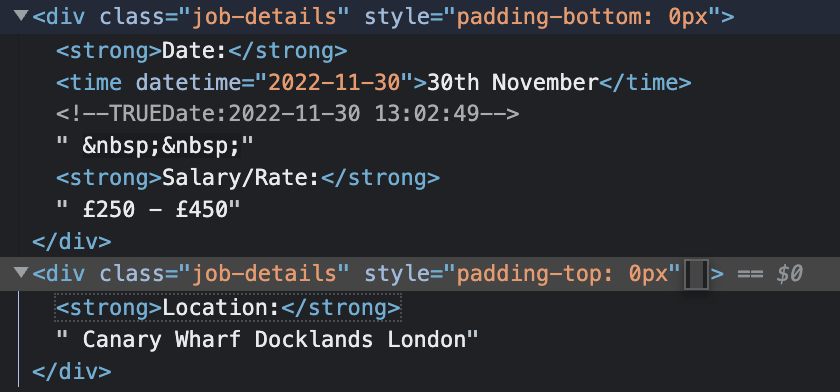
I have tried to extract the location data from the website, for a webscraping project I am trying to do. Sadly I am not able to scrape salary. Only the location and date.
Can anyone help me?
I was going to scrape using python then convert to SQL. Sadly I am not able to find a way to get the location aswell.
from bs4 import BeautifulSoup
import requests
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
postList = []
def getPosts(page):
url = url = 'https://www.technojobs.co.uk/search.phtml?page={page}&row_offset=10&keywords=data analyst&salary=0&jobtype=all&postedwithin=all'
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
posts = soup.find_all('div', {'class': 'jobbox'})
for item in posts:
post = {
'title': item.find('div', {'class': 'job-ti'}).text,
'dateSalaryLocation': item.find('div', {'class': 'job-details'}).text,
'description': item.find('div', {'class': 'job-body'}).text,
}
postList.append(post)
return
for x in range(1, 37):
getPosts(x)
df = pd.DataFrame(postList)
df.to_csv('TechnoJobs.csv', index=False, encoding='utf-8')
CodePudding user response:
Elements are spreaded over two elements with same class, so you could select them one after the other or you try to generalise, select all <strong> as key and its next_sibling as value to create a dict:
for item in posts:
post = {
'title': item.find('div', {'class': 'job-ti'}).text,
'description': item.find('div', {'class': 'job-body'}).text,
}
post.update(
{(x.text[:-1],x.next_sibling) if x.text[:-1] != 'Date' else (x.text[:-1],x.find_next_sibling().text) for x in item.select('.job-details strong')}
)
postList.append(post)
Example
from bs4 import BeautifulSoup
import requests
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
postList = []
def getPosts(page):
url = url = 'https://www.technojobs.co.uk/search.phtml?page={page}&row_offset=10&keywords=data analyst&salary=0&jobtype=all&postedwithin=all'
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
posts = soup.find_all('div', {'class': 'jobbox'})
for item in posts:
post = {
'title': item.find('div', {'class': 'job-ti'}).text,
'description': item.find('div', {'class': 'job-body'}).text,
}
post.update(
{(x.text[:-1],x.next_sibling) if x.text[:-1] != 'Date' else (x.text[:-1],x.find_next_sibling().text) for x in item.select('.job-details strong')}
)
postList.append(post)
return
for x in range(1, 2):
getPosts(x)
pd.DataFrame(postList)
Output
| title | description | Date | Salary/Rate | Location | |
|---|---|---|---|---|---|
| 0 | Data Analyst with Big Data | Job Description Data Analyst with Big Data - Canary Wharf Our Client is seeking a Data Analyst for the Data Products team is driving innovations in the Financial Services Sector using Big Data. The Client has a high-calibre, focused and a mission-driven team. The models we build and the analysis that we derive from financial data matters to crucial... | 24th November | £300 - £450 | Canary Wharf London |
| 1 | Data Analyst with Big Data | Data Analyst with Big Data - Canary Wharf Our Client is seeking a Data Analyst for the Data Products team is driving innovations in the Financial Services Sector using Big Data. The Client has a high-caliber, focused and a mission-driven team. The models we build and the analysis that we derive from financial data matters to crucial cutting-edge... | 30th November | £250 - £450 | Canary Wharf Docklands London |
| 2 | ESA - Perm - Data analyst BI - DATA | Nous recherchons des personnes avec une dimension hybride : ayant à la fois une connaissance avancée d'une ou plusieurs solutions BI/ Dataviz, capable de travailler en relation directe avec des équipes métier et être capable de piloter des projets data. Vous serez amené à: Travailler en mode agile et en autonomie, avec des sprints très courts... | 25th November | £45,180 - £63,252 | Paris |
...
CodePudding user response:
import requests
from bs4 import BeautifulSoup, SoupStrainer
from concurrent.futures import ThreadPoolExecutor, as_completed
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0'
}
def get_soup(content):
return BeautifulSoup(content, 'lxml', parse_only=SoupStrainer('div', attrs={'class': 'jobbox'}))
def worker(req, page):
params = {
"jobtype": "all",
"keywords": "data analyst",
"page": page,
"postedwithin": "all",
"row_offset": "10",
"salary": "0"
}
while True:
try:
r = req.get(
'https://www.technojobs.co.uk/search.phtml', params=params)
if r.ok:
break
except requests.exceptions.RequestException:
continue
soup = get_soup(r.content)
print(f'Extracted Page# {page}')
return [
(
x.select_one('.job-ti a').get_text(strip=True, separator=' '),
x.select_one('.job-body').get_text(strip=True, separator=' '),
list(x.select_one(
'strong:-soup-contains("Salary/Rate:")').next_elements)[1].get_text(strip=True),
list(x.select_one(
'strong:-soup-contains("Location:")').next_elements)[1].get_text(strip=True)
)
for x in soup.select('.jobbox')
]
def main():
with requests.Session() as req, ThreadPoolExecutor() as executor:
req.headers.update(headers)
futures = (executor.submit(worker, req, page) for page in range(1, 38))
allin = []
for res in as_completed(futures):
allin.extend(res.result())
df = pd.DataFrame(
allin, columns=['Name', 'Description', 'Salary', 'Location'])
# df.to_sql()
print(df)
main()
Output:
Name ... Location
0 Junior Data Insights Analyst ... Knutsford
1 Data Insight Analyst ... Knutsford
2 Senior Data Insight Analyst ... Knutsford
3 Business Data Analyst ... Glasgow
4 Data Analyst with VBA and SQL ... Docklands London
.. ... ... ...
331 Power Platform Business Analyst ... Manchester
332 Power Platform Business Analyst ... Glasgow
333 Power Platform Business Analyst ... Birmingham
334 Cyber Security Compliance Analyst ... London
335 |Sr Salesforce Admin/ PM| $120,000|Remote| ... New York
[336 rows x 4 columns]