I have a dataset given as such in Python:
#Load the required libraries
import pandas as pd
#Create dataset
data = {'id': [1, 1, 1, 1, 1,1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3],
'runs': [6, 6, 6, 6, 6,6,7,8,9,10, 3, 3, 3,4,5,6, 5, 5,5, 5,5,6,7,8],
'Children': ['No', 'Yes', 'Yes', 'Yes', 'No','No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'No'],
'Days': [123, 128, 66, 120, 141,123, 128, 66, 120, 141, 52,96, 120, 141, 52,96, 120, 141,123,15,85,36,58,89],
}
#Convert to dataframe
df = pd.DataFrame(data)
print("df = \n", df)
The above dataframe looks as such :
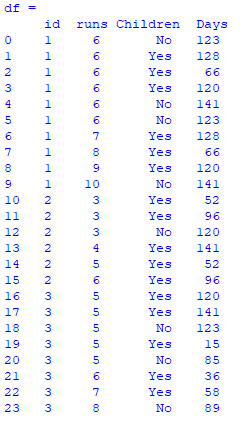
Here, for every 'id', I wish to truncate the columns where 'runs' are being repeated and make the numbering continuous in that id.
For example,
For id=1, truncate the 'runs' at 6 and re-number the dataset starting from 1.
For id=2, truncate the 'runs' at 3 and re-number the dataset starting from 1.
For id=3, truncate the 'runs' at 5 and re-number the dataset starting from 1.
The net result needs to look as such:
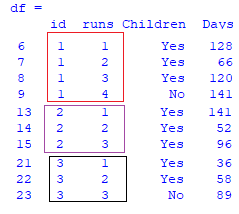
Can somebody please let me know how to achieve this task in python?
I wish to truncate and re-number a column that corresponds to a specific id/group by using Python
CodePudding user response:
Filter out the duplicates with loc and duplicated, then renumber with groupby.cumcount:
out = (df[~df.duplicated(subset=['id', 'runs'], keep=False)]
.assign(runs=lambda d: d.groupby(['id']).cumcount().add(1))
)
Output:
id runs Children Days
6 1 1 Yes 128
7 1 2 Yes 66
8 1 3 Yes 120
9 1 4 No 141
13 2 1 Yes 141
14 2 2 Yes 52
15 2 3 Yes 96
21 3 1 Yes 36
22 3 2 Yes 58
23 3 3 No 89
CodePudding user response:
You can create a loop to go through each id and run cutoff value, and for each iteration of the loop, determine the new segment of your dataframe by the id and run values of the original dataframe, and append the new dataframe to your final dataframe.
df_truncated = pd.DataFrame(columns=df.columns)
for id,run_cutoff in zip([1,2,3],[6,3,5]):
df_chunk = df[(df['id'] == id) & (df['runs'] > run_cutoff)].copy()
df_chunk['runs'] = range(1, len(df_chunk) 1)
df_truncated = pd.concat([df_truncated, df_chunk])
Result:
id runs Children Days
6 1 1 Yes 128
7 1 2 Yes 66
8 1 3 Yes 120
9 1 4 No 141
13 2 1 Yes 141
14 2 2 Yes 52
15 2 3 Yes 96
21 3 1 Yes 36
22 3 2 Yes 58
23 3 3 No 89