I have a dataset given as such:
#Load the required libraries
import pandas as pd
#Create dataset
data = {'team': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A'],
'Run_time': [1, 2, 3, 4, 5, 1, 2, 3, 1, 2, 3, 4],
'Married': ['No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'No'],
'Self_Employed': ['No', 'No', 'Yes', 'No', 'No', 'No', 'Yes', 'No', 'No', 'Yes', 'No', 'No'],
'LoanAmount': [123, 128, 66, 120, 141, 52,96,15,85,36,58,89],
}
#Convert to dataframe
df = pd.DataFrame(data)
print("df = \n", df)
The dataset looks as such:
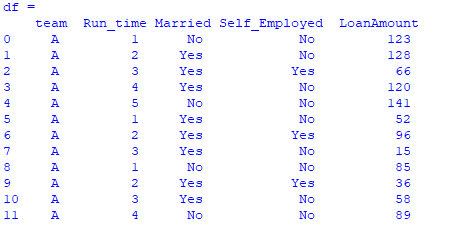
Here, in the 'Run_time' column, the numbering starts at different index values.
I wish to ensure that the 'Run_time' column starts from 1 only.
The dataset needs to look as such:
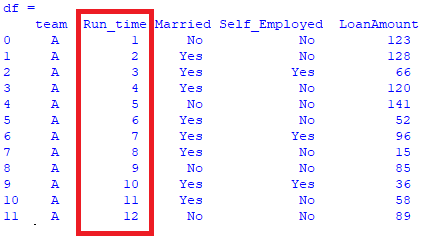
Can somebody please let me know how to modify this column in Python such that the numbering is continuous?
CodePudding user response:
import pandas as pd
#Create dataset
data = {'team': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A'],
'Run_time': [1, 2, 3, 4, 5, 1, 2, 3, 1, 2, 3, 4],
'Married': ['No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'Yes', 'No'],
'Self_Employed': ['No', 'No', 'Yes', 'No', 'No', 'No', 'Yes', 'No', 'No', 'Yes', 'No', 'No'],
'LoanAmount': [123, 128, 66, 120, 141, 52,96,15,85,36,58,89],
}
#Convert to dataframe
df = pd.DataFrame(data)
# print("df = \n", df)
df.Run_time = df.index 1
df