I have a long data frame with a lot of NA's.
I would like to find the ratio of the value of Column A and Column D. How do I only select the rows where there's data present in both Column A and Column D?
As an example, in this image I want to only compare the values of rows 2,4,6 for Columns A and D.
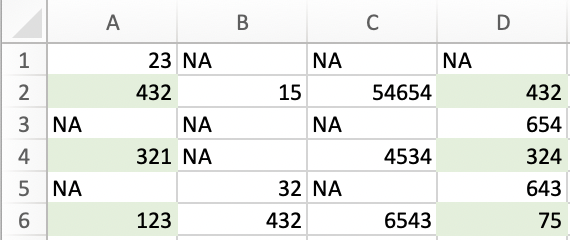
I can use na.omit on each row, but I'm not sure how to ask R to find the rows where data is present in both columns.
CodePudding user response:
Like so:
library(tidyverse)
df <- data.frame(col1=c(1, NA, 7), col2=c(NA, 2, 5))
# col1 col2
# 1 1 NA
# 2 NA 2
# 3 7 5
df %>%
filter(!is.na(col1) & !is.na(col2))
#
# col1 col2
# 1 7 5
CodePudding user response:
Here are some options using base R.
Using is.na():
df[!is.na(df$A) & !is.na(df$D), ]
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
Using complete.cases():
df[complete.cases(df$A, df$D), ]
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
Using subset():
subset(df, complete.cases(A, D))
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
Here are a couple of other options using the tidyverse.
Using drop_na() from tidyr:
library(dplyr)
library(tidyr)
df %>%
drop_na(A, D)
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
Using complete.cases() with filter() from dplyr (this one is actually my preference for readability):
library(dplyr)
df %>%
filter(complete.cases(A, D))
# A B C D
# 1 432 15 54654 432
# 2 321 NA 4534 324
# 3 123 432 6543 75
Data:
df <- data.frame(A = c(23, 432, NA, 321, NA, 123),
B = c(NA, 15, NA, NA, 32, 432),
C = c(NA, 54654, NA, 4534, NA, 6543),
D = c(NA, 432, 654, 324, 643, 75))
CodePudding user response:
To only get the values you can simply:
(df$A / df$D)[!is.na(df$A / df$D)]
[1] 1.0000000 0.9907407 1.6400000
This puts the values as an additional column:
cbind( df, df$A / df$D )
A B C D df$A/df$D
1 23 NA NA NA NA
2 432 15 54654 432 1.0000000
3 NA NA NA 654 NA
4 321 NA 4534 324 0.9907407
5 NA 32 NA 643 NA
6 123 432 6543 75 1.6400000