Im trying to web scrape github
This is the code:
import requests as req
from bs4 import BeautifulSoup
urls = [
"https://github.com/moom825/Discord-RAT",
"https://github.com/freyacodes/Lavalink",
"https://github.com/KagChi/lavalink-railways",
"https://github.com/KagChi/lavalink-repl",
"https://github.com/Devoxin/Lavalink.py",
"https://github.com/karyeet/heroku-lavalink"]
r = req.get(urls[0])
soup = BeautifulSoup(r.content,"lxml")
title = str(soup.find("p",attrs={"class":"f4 mt-3"}).text)
print(title)
When i run the program i don't get any kind of errors but the indentation is very weird
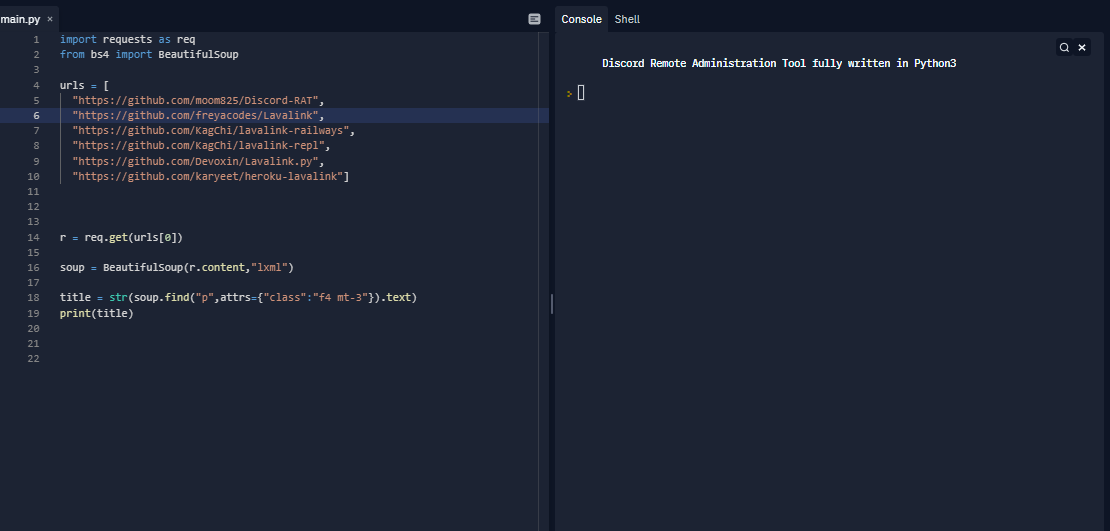
Please anyone help me with this problem Im using replit
CodePudding user response:
Github has a really good API
You can use .strip() after .text then it will remove whitespace.
import requests as req
from bs4 import BeautifulSoup
urls = [
"https://github.com/moom825/Discord-RAT",
"https://github.com/freyacodes/Lavalink",
"https://github.com/KagChi/lavalink-railways",
"https://github.com/KagChi/lavalink-repl",
"https://github.com/Devoxin/Lavalink.py",
"https://github.com/karyeet/heroku-lavalink"]
r = req.get(urls[0])
soup = BeautifulSoup(r.content,"lxml")
title = str(soup.find("p",attrs={"class":"f4 mt-3"}).text.strip())
print(title)