I have two data frames with the same date index and columns. I would like to find the cases where a column has a value in one data frame but has a NaN in the other.
From the two data frames below then I would like to be able to retrieve an output for a given column that would look like this:
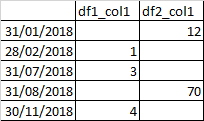
Or for the second column like:
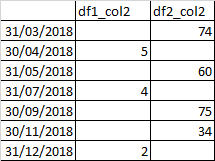
import pandas as pd
import numpy as np
dt_range = pd.date_range("2018-01-31", periods=12, freq="M")
df_1 = pd.DataFrame(data={'col1': [np.nan,1,7,5,np.nan,6,3,np.nan,8,8,4,2],
'col2': [6,7,np.nan,5,np.nan,8,4,9,np.nan,8,np.nan,2],
'col3': [9,6,np.nan,7,5,8,np.nan,9,np.nan,8,6,6]},
index=dt_range)
df_2 = pd.DataFrame(data={'col1': [12,np.nan,70,58,np.nan,61,np.nan,70,85,85,np.nan,42],
'col2': [22,26,74,np.nan,60,21,np.nan,20,75,55,34,np.nan],
'col3': [93,np.nan,47,52,85,np.nan,29,np.nan,81,16,46,np.nan]},
index=dt_range)
CodePudding user response:
First, we use the merge method on the index values like so :
>>> df = pd.merge(df_1,
... df_2,
... how='left',
... left_index=True,
... right_index=True,
... suffixes=['_df_1',
... '_df_2'])
>>> df.head()
col1_df_1 col2_df_1 col3_df_1 col1_df_2 col2_df_2 col3_df_2
2018-01-31 NaN 6.0 9.0 12.0 22.0 93.0
2018-02-28 1.0 7.0 6.0 NaN 26.0 NaN
2018-03-31 7.0 NaN NaN 70.0 74.0 47.0
2018-04-30 5.0 5.0 7.0 58.0 NaN 52.0
2018-05-31 NaN NaN 5.0 NaN 60.0 85.0
Then we write a function to select the two columns and the rows where one column has value and the other is missing to get the expected result :
>>> def compare_columns_with_nan(col_name):
... return df[((df[f'{col_name}_df_1'].isna()) | (df[f'{col_name}_df_2'].isna())) & ~((df[f'{col_name}_df_1'].isna()) & (df[f'{col_name}_df_2'].isna()))][[f'{col_name}_df_1', f'{col_name}_df_2']]
Output for col1 :
>>> compare_columns_with_nan('col1')
col1_df_1 col1_df_2
2018-01-31 NaN 12.0
2018-02-28 1.0 NaN
2018-07-31 3.0 NaN
2018-08-31 NaN 70.0
2018-11-30 4.0 NaN
Output for col2 :
>>> compare_columns_with_nan('col2')
col2_df_1 col2_df_2
2018-03-31 NaN 74.0
2018-04-30 5.0 NaN
2018-05-31 NaN 60.0
2018-07-31 4.0 NaN
2018-09-30 NaN 75.0
2018-11-30 NaN 34.0
2018-12-31 2.0 NaN