I have this pandas.core.series.Series after grouping by 2 columns case and area
| case | area | |
|---|---|---|
| A | 1 | 2494 |
| 2 | 2323 | |
| B | 1 | 59243 |
| 2 | 27125 | |
| 3 | 14 |
I want to keep only areas that are in case A , that means the result should be like this:
| case | area | |
|---|---|---|
| A | 1 | 2494 |
| 2 | 2323 | |
| B | 1 | 59243 |
| 2 | 27125 |
I tried this code :
a = df['B'][~df['B'].index.isin(df['A'].index)].index
df['B'].drop(a)
And it worked, the output was :
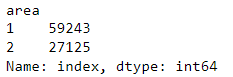
But it didn't drop it in the dataframe, it still the same.
when I assign the result of droping, all the values became NaN
df['B'] = df['B'].drop(a)
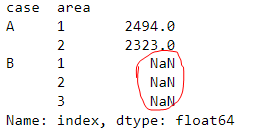
what should I do ?
CodePudding user response:
it is possible to drop after grouping, here's one way
import pandas
import numpy as np
np.random.seed(1)
ungroup_df = pd.DataFrame({
'case':[
'A','A','A','A','A','A',
'A','A','A','A','A','A',
'B','B','B','B','B','B',
'B','B','B','B','B','B',
],
'area':[
1,2,1,2,1,2,
1,2,1,2,1,2,
1,2,3,1,2,3,
1,2,3,1,2,3,
],
'value': np.random.random(24),
})
df = ungroup_df.groupby(['case','area'])['value'].sum()
print(df)
#index into the multi-index to just the 'A' areas
#the ":" is saying any value at the first level (A or B)
#then the df.loc['A'].index is filtering to second level of index (area) that match A's
filt_df = df.loc[:,df.loc['A'].index]
print(filt_df)
Test df:
case area
A 1 1.566114
2 2.684593
B 1 1.983568
2 1.806948
3 2.079145
Name: value, dtype: float64
Output after dropping
case area
A 1 1.566114
2 2.684593
B 1 1.983568
2 1.806948
Name: value, dtype: float64