I have two pandas dataframes, called data and data1 (which I extracted both from an unestructured excel file).
data is a one row dataframe. data1 is a multiple row dataframe (it will vary depending on the original excel file).
What I want to achieve is to concatenate both, but the values from data repeat for each row in data1. resulting like this:
| data | data | data | data1 | data1 | data1 |
|---|---|---|---|---|---|
| One | Two | Three | asda | dsad | dsass |
| One | Two | Three | dsad | dasda | dasds |
| One | Two | Three | asda | asdsss | dsass |
| One | Two | Three | adsa | dsad | asdds |
Is there an efficient way to do this? I've been doing it manually, but it is taking too long because there are like 1k files.
Best regards.
CodePudding user response:
You can do something like this:
data = pd.DataFrame(data = ['One', 'Two', 'Three'])
data = data.T
data1 = pd.DataFrame({"col1": ['asda', 'dsad', 'adsa'],
"col2": ['dsad', 'dasda', 'asdsss'],
"col3": ['dsass', 'dasds', 'asdds']})
data.merge(data1, how = 'cross')
which should give:
0 1 2 col1 col2 col3
0 One Two Three asda dsad dsass
1 One Two Three dsad dasda dasds
2 One Two Three adsa asdsss asdds
It's then kind of down to you how you want to deal with your column names. You cannot have more than one column with the same name so data can't be reused. You can either directly rename them after data.merge(...) (which is probably cleaner) or use
data.merge(data1, how = 'cross', suffixes = ("_data", "data1"))
but this will only have an effect if the column names in the two dataframes match. E.g.
data = pd.DataFrame(data = ['One', 'Two', 'Three'])
data = data.T
data.columns = ['col1', 'col2', 'col3']
data1 = pd.DataFrame({"col1": ['asda', 'dsad', 'adsa'],
"col2": ['dsad', 'dasda', 'asdsss'],
"col3": ['dsass', 'dasds', 'asdds']})
data.merge(data1, how = 'cross', suffixes = ("_data", "_data1"))
which gives
col1_data col2_data col3_data col1_data1 col2_data1 col3_data1
0 One Two Three asda dsad dsass
1 One Two Three dsad dasda dasds
2 One Two Three adsa asdsss asdds
CodePudding user response:
Try something like this:
pd.concat([data.reindex(data.index.repeat(len(data1))).reset_index(drop=True),
data1],
axis=1,
ignore_index=True)
Details:
- Repeat the one row index of data for the number of rows in data1.
- Reindex data to expand the size the number of rows in data and drop repeated index.
- Concatenate data with data1 using axis=1.
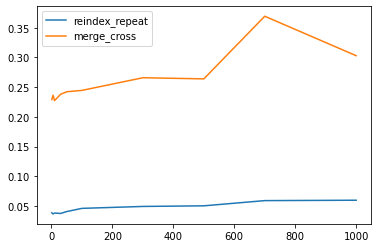
Timing Test
import pandas as pd
import numpy as np
import timeit
import matplotlib.pyplot as plt
import pandas.testing as pt
data = pd.DataFrame(data = [['One', 'Two', 'Three']], columns=['a','b','c'])
data1 = pd.DataFrame({"col1": ['asda', 'dsad', 'adsa'],
"col2": ['dsad', 'dasda', 'asdsss'],
"col3": ['dsass', 'dasds', 'asdds']})
def reindex_repeat(data1):
return pd.concat([data.reindex(data.index.repeat(len(data1))).reset_index(drop=True),
data1],
axis=1)
def merge_cross(data1):
return data.merge(data1, how = 'cross')
pt.assert_frame_equal(merge_cross(data1), reindex_repeat(data1))
fig, ax = plt.subplots()
res = pd.DataFrame(
index=[1, 5, 10, 30, 50, 100, 300, 500, 700, 1000],
columns='reindex_repeat merge_cross'.split(),
dtype=float
)
for i in res.index:
d = pd.concat([data1]*i, ignore_index=True)
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit.timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=False, ax=ax);
Chart Output: