I have numbers in a List that should get assigned to certain rows of a dataframe consecutively.
List=[2,5,7,12….]
In my dataframe that looks similar to the below table, I need to do the following:
A frame_index that starts with 1 gets the next element of List as “sequence_number”
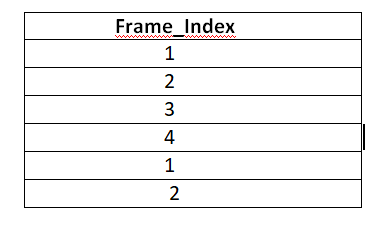
Frame_Index==1 then assign first element of List as Sequence_number.
Frame_index == 1 again, so assign second element of List as Sequence_number.
So my goal is to achieve a new dataframe like this:
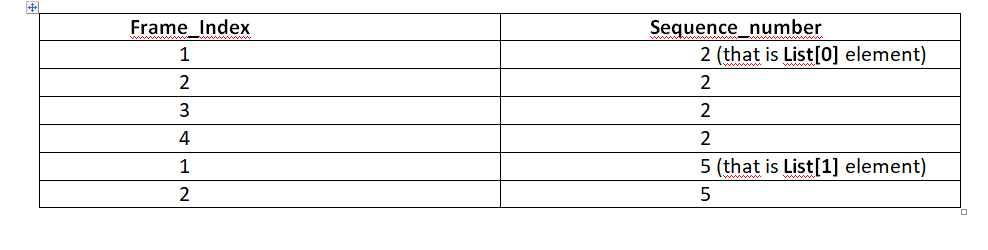
I don't know which functions to use. If this weren't python language, I would use a for loop and check where frame_index==1, but my dataset is large and I need a pythonic way to achieve the described solution. I appreciate any help.
EDIT: I tried the following to fill with my List values to use fillna with ffill afterwards:
concatenated_df['Sequence_number']=[List[i] for i in
concatenated_df.index if (concatenated_df['Frame_Index'] == 1).any()]
But of course I'm getting "list index out of range" error.
CodePudding user response:
I think you could do that in two steps.
- Add column and fill with your list where frame_index == 1.
- Use df.fillna() with
method="ffill"kwarg.
import pandas as pd
df = pd.DataFrame({"frame_index": [1,2,3,4,1,2]})
sequence = [2,5]
df.loc[df["frame_index"] == 1, "sequence_number"] = sequence
df.ffill(inplace=True) # alias for df.fillna(method="ffill")
This puts the sequence_number as float64, which might be acceptable in your use case, if you want it to be int64, then you can just force it when creating the column (line 4) or cast it later.