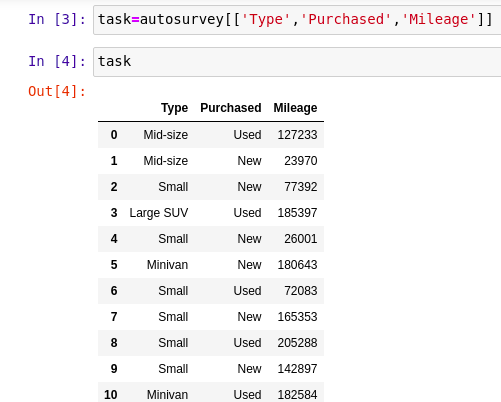
This is how my dataframe looks like. Now i want to calculate the average mileage for used and new type. The sample output is like this.
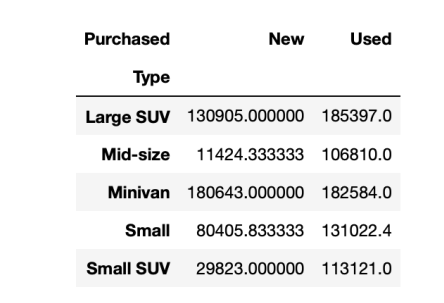
here is my data and i want the dataframe as sample output
Gender Type Purchased Vehicle_Age Mileage MPG
0 Male Mid-size Used 15.00 127233 28.7
1 Female Mid-size New 1.00 23970 43.4
2 Male Small New 7.00 77392 24.0
3 Female Large SUV Used 14.00 185397 15.2
4 Female Small New 2.00 26001 37.0
5 Female Minivan New 9.00 180643 20.0
6 Male Small Used 6.00 72083 45.7
7 Male Small New 11.00 165353 42.0
8 Male Small Used 13.00 205288 33.0
9 Female Small New 7.00 142897 31.0
10 Male Minivan Used 14.00 182584 12.0
11 Male Small SUV Used 13.00 140479 20.0
12 Female Small New 2.00 22114 28.0
13 Female Mid-size New 0.25 3454 28.3
14 Female Large SUV New 7.00 130905 21.0
15 Female Small Used 10.00 105628 35.0
16 Female Small New 5.00 48678 30.4
17 Male Mid-size New 0.50 6849 40.2
18 Female Small Used 10.00 137941 30.0
19 Female Small SUV New 4.00 29823 24.9
20 Male Small SUV Used 14.00 85763 21.0
21 Female Small Used 12.00 134172 31.0
22 Male Mid-size Used 12.00 86387 27.0
CodePudding user response:
Alright, you can do this with pivot_table:
import pandas as pd
data = [ { "idx": 0, "Type": "Mid-size", "Purchased": "Used", "Mileage": 127233 }, { "idx": 1, "Type": "Mid-size", "Purchased": "New", "Mileage": 23970 }, { "idx": 2, "Type": "Small", "Purchased": "New", "Mileage": 77392 }, { "idx": 3, "Type": "Large SUV", "Purchased": "Used", "Mileage": 185397 }, { "idx": 4, "Type": "Small", "Purchased": "New", "Mileage": 26001 }, { "idx": 5, "Type": "Minivan", "Purchased": "New", "Mileage": 180643 }, { "idx": 6, "Type": "Small", "Purchased": "Used", "Mileage": 72083 }, { "idx": 7, "Type": "Small", "Purchased": "New", "Mileage": 165353 }, { "idx": 8, "Type": "Small", "Purchased": "Used", "Mileage": 205288 }, { "idx": 9, "Type": "Small", "Purchased": "New", "Mileage": 142897 }, { "idx": 10, "Type": "Minivan", "Purchased": "Used", "Mileage": 182584 } ]
df = pd.DataFrame(data).set_index('idx')
df = pd.pivot_table(df, index=['Type'], columns=['Purchased'], aggfunc='mean', fill_value=0, values='Mileage')
Output:
| Type | New | Used |
|---|---|---|
| Large SUV | 0 | 185397 |
| Mid-size | 23970 | 127233 |
| Minivan | 180643 | 182584 |
| Small | 102911 | 138686 |
CodePudding user response:
df.pivot_table(index='Type',columns='Purchased',values='Mileage')