I have 2 data frames df1 and df2.
import pandas as pd
df1 = pd.DataFrame({
'id':['1','1','1','2','2','2', '3', '4','4', '5', '6', '7'],
'group':['A','A','B', 'A', 'A', 'C', 'A', 'A', 'B', 'B', 'A', 'C']
})
df2 = pd.DataFrame({
'id':['1','2','3','4','5','6','7']
})
I want to add 3 columns to df2 named group_A, group_B, and group_C, where each counts the number of repetitions of each group in df1 according to the id column. so the result of df2 should be likes this:
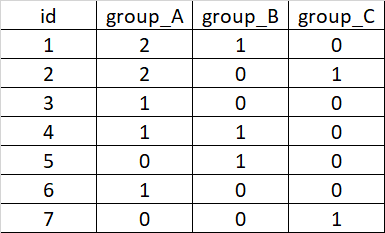
CodePudding user response:
Use crosstab with DataFrame.join, type of both id has to by same, like here strings:
print (pd.crosstab(df1['id'], df1['group']).add_prefix('group_'))
group group_A group_B group_C
id
1 2 1 0
2 2 0 1
3 1 0 0
4 1 1 0
5 0 1 0
6 1 0 0
7 0 0 1
df = df2.join(pd.crosstab(df1['id'], df1['group']).add_prefix('group_'), on='id')
print (df)
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
Solution without join is possible, if same ids in both DataFrames:
print (pd.crosstab(df1['id'], df1['group']).add_prefix('group_').reset_index().rename_axis(None, axis=1))
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
CodePudding user response:
One option is to get the counts for df2, before joining to df1:
counts = df1.value_counts().unstack(fill_value=0).add_prefix('group_')
df2.join(counts, on='id')
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
Another option is with get_dummies, combined with groupby:
counts = pd.get_dummies(df1, columns = ['group']).groupby('id').sum()
df2.join(counts, on='id')
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1