i have a log(detection.csv) of detected class in a script
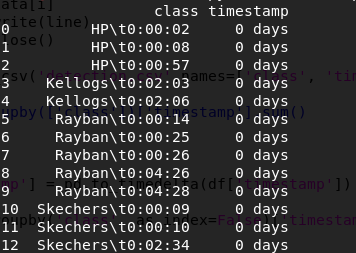
HP,0:00:08
Kellogs,0:02:03
Rayban,0:00:25
Skechers,0:00:09
Rayban,0:04:26
Skechers,0:02:34
HP,0:00:57
Rayban,0:00:14
HP,0:00:02
HP,0:00:08
Kellogs,0:02:06
Rayban,0:00:26
Skechers,0:00:10
The question is is there an way to sum up the time-duration of detected class with using pandas.groupby() method or any other method
Note: both columns are in format of strings
when i am using pandas.groupby()method the result is not summing up
OverallCode:
import numpy as np
import pandas as pd
csvdata=[]
with open('result2.txt','r ') as myfile:
for lines in myfile:
line=myfile.read()
line=line.replace(' ',',')
csvdata.append(line)
#print(csvdata)
with open('detection.csv','w') as newfile:
for i in range(len(csvdata)):
line=csvdata[i]
newfile.write(line)
newfile.close()
df=pd.read_csv('detection.csv',names=['class', 'timestamp'],header=None)
#ndf=df.groupby(['class'])['timestamp'].sum()
#print(ndf)
df['timestamp'] = pd.to_timedelta(df['timestamp'])
def format_timedelta(x):
ts = x.total_seconds()
hours, remainder = divmod(ts, 3600)
minutes, seconds = divmod(remainder, 60)
return ('{}:{:02d}:{:02d}').format(int(hours), int(minutes), int(seconds))
df1 = df.groupby('class')['timestamp'].sum().apply(format_timedelta).reset_index()
print (df1)
CodePudding user response:
Yes, it is possible with convert column to timedeltas by to_timedelta and aggregate sum:
df['time'] = pd.to_timedelta(df['time'])
df1 = df.groupby('company', as_index=False)['time'].sum()
print (df1)
company time
0 HP 0 days 00:01:15
1 Kellogs 0 days 00:04:09
2 Rayban 0 days 00:05:31
3 Skechers 0 days 00:02:53
For original format use custom function:
df['time'] = pd.to_timedelta(df['time'])
def format_timedelta(x):
ts = x.total_seconds()
hours, remainder = divmod(ts, 3600)
minutes, seconds = divmod(remainder, 60)
return ('{}:{:02d}:{:02d}').format(int(hours), int(minutes), int(seconds))
df1 = df.groupby('company')['time'].sum().apply(format_timedelta).reset_index()
print (df1)
company time
0 HP 0:01:15
1 Kellogs 0:04:09
2 Rayban 0:05:31
3 Skechers 0:02:53
EDIT: You can simplify your code:
csvdata=[]
with open('result2.txt','r ') as myfile:
for lines in myfile:
line=myfile.read()
line=line.replace(' ',',')
csvdata.append(line)
#print(csvdata)
with open('detection.csv','w') as newfile:
for i in range(len(csvdata)):
line=csvdata[i]
newfile.write(line)
newfile.close()
df=pd.read_csv('result2.csv',names=['class', 'timestamp'],header=None)
to:
#convert txt with tab separator
df=pd.read_csv('result2.txt',names=['class', 'timestamp'],header=None, sep='\t')