I can't figure out how to make it work. Some people asked similar questions in r-forums but it seems my understanding is to basic to make the transfer. I have a large repeated measures dataset in long format and i performed a cluster-analysis. Now I need to copy the value signalling group-membership inside the second column based on Participant-ID. The table underneath shows how it looks at the moment. I need to automatically fill in the blank spaces for cluster_membership with the same values depending on the id.
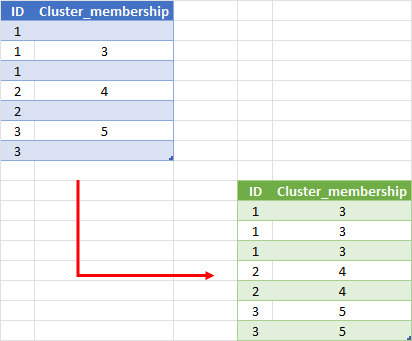
| ID | Cluster_membership |
|---|---|
| 1 | |
| 1 | 3 |
| 1 | |
| 2 | 4 |
| 2 | |
| 3 | 5 |
| 3 |
| ID | Cluster_membership that i need |
|---|---|
| 1 | 3 |
| 1 | 3 |
| 1 | 3 |
| 2 | 4 |
| 2 | 4 |
| 3 | 5 |
| 3 | 5 |
Thank you in advance, Philipp
CodePudding user response:
If your data is as you show it, with only a single Cluster_membership per ID, you can obtain your desired output using Power Query, available in Windows Excel 2010 and Office 365 Excel
- Select some cell in your original table
Data => Get&Transform => From Table/Range- When the PQ UI opens, navigate to
Home => Advanced Editor - Make note of the Table Name in Line 2 of the code.
- Replace the existing code with the M-Code below
- Change the table name in line 2 of the pasted code to your "real" table name
- Examine any comments, and also the
Applied Stepswindow, to better understand the algorithm and steps
M Code
let
//change table name in next line to actual name in your workbook
Source = Excel.CurrentWorkbook(){[Name="Table11"]}[Content],
#"Changed Type" = Table.TransformColumnTypes(Source,{{"ID", Int64.Type}, {"Cluster_membership", Int64.Type}}),
//Group by ID and extract Cluster_membership
#"Grouped Rows" = Table.Group(#"Changed Type", {"ID"}, {
{"all", each _, type table [ID=nullable number, Cluster_membership=nullable number]},
{"Cluster_membership", each List.Max([Cluster_membership])}
}),
//remove unneeded columns and expand the resultant table (except for the Cluster_membership column
#"Removed Columns" = Table.RemoveColumns(#"Grouped Rows",{"ID"}),
#"Expanded all" = Table.ExpandTableColumn(#"Removed Columns", "all", {"ID"}, {"ID"})
in
#"Expanded all"
Note:
Another way of getting the same output would be to
- Sort the table by ID and then cluster
- Fill-Up the cluster column
I'm not sure which will be faster on your data set. The code with sorting is simpler, but sorting sometimes takes a while in PQ. You can try both methods. If you do, please let me know the results of comparison
M Code (sort method)
let
//change table name in next line to actual name in your workbook
Source = Excel.CurrentWorkbook(){[Name="Table11"]}[Content],
#"Changed Type" = Table.TransformColumnTypes(Source,{{"ID", Int64.Type}, {"Cluster_membership", Int64.Type}}),
//sort by ID and cluster, then fill-up
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"ID", Order.Ascending}, {"Cluster_membership", Order.Ascending}}),
#"Filled Up" = Table.FillUp(#"Sorted Rows",{"Cluster_membership"})
in
#"Filled Up"