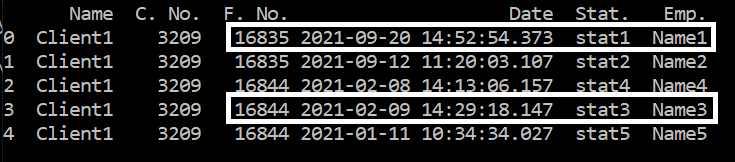
There's an excel file with above 200,000 rows and I would like to extract the first row only from each group (the groups are in the third column. I have read the dataset and sorted the values by two columns. Now I just need to create a new dataframe with the first row of each group

This is sample of the excel file and here's my attempt till now
import pandas as pd
df = pd.read_excel('Example.xlsx', sheet_name='Sheet1')
df['Date']= pd.to_datetime(df['Date'])
df = df.sort_values(['F. No.', 'Date'], ascending=[True, False])
print(df.head())
So I need to extract the four columns starting from F. No. to Emp. (the most recent records only for each group)
CodePudding user response:
This might help:
import pandas as pd
df = pd.read_excel('Example.xlsx', sheet_name='Sheet1')
df['Date']= pd.to_datetime(df['Date'])
df = df.sort_values(['F. No.', 'Date'], ascending=[True, False])
df_first = df.groupby(['F. No.'], as_index=False).head(1)
To make sure that the groupby column does not become an index, pass as_index=False kwarg. Note that .head(1) works because the data is sorted in the previous line.