i want to get the informatiom from booking.com (like hotel names, prices...), but I cannot find these information when I access the website through python using BeautifulSoup.
This is what I did:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import requests
url="https://www.booking.com/searchresults.en-gb.html?label=gen173nr-1DCAEoggI46AdIM1gEaGKIAQGYAQm4AQfIAQzYAQPoAQGIAgGoAgO4AtDrhJMGwAIB0gIkZjQzNmY0MTQtMjY3OS00NGE0LTkwOWEtNGQ3YzQ0OTY1Mjc42AIE4AIB&lang=en-gb&sid=b9d75b447deb2624c8cfaadad9969120&sb=1&sb_lp=1&src=index&src_elem=sb&error_url=https://www.booking.com/index.en-gb.html?label=gen173nr-1DCAEoggI46AdIM1gEaGKIAQGYAQm4AQfIAQzYAQPoAQGIAgGoAgO4AtDrhJMGwAIB0gIkZjQzNmY0MTQtMjY3OS00NGE0LTkwOWEtNGQ3YzQ0OTY1Mjc42AIE4AIB;sid=b9d75b447deb2624c8cfaadad9969120;sb_price_type=total&;&ss=Hong Kong&is_ski_area=0&ssne=Hong Kong&ssne_untouched=Hong Kong&dest_id=-1353149&dest_type=city&checkin_year=2022&checkin_month=4&checkin_monthday=25&checkout_year=2022&checkout_month=4&checkout_monthday=30&group_adults=2&group_children=0&no_rooms=1&b_h4u_keep_filters=&from_sf=1"
requests.get(url)
response = requests.get(url)
response.status_code
soup = BeautifulSoup(response.content,'html.parser')
print(soup)
after I print soup, I can only see the information like scores but I cannot find anything about the hotel names when I use find(), can you tell me what I did wrong and how can I do it right? Thank you so much!!
CodePudding user response:
You just simply need to inspect the HTML of the page that is returned in the soup, for example if you inspect hotel heading in the browser you will notice top 10 results of hotels are being shown in the tag with class of card
Then finally you can use find to fetch all the info e.g. check the following modified version of your code
from bs4 import BeautifulSoup
from urllib.request import urlopen
import requests
url="https://www.booking.com/searchresults.en-gb.html?label=gen173nr-1DCAEoggI46AdIM1gEaGKIAQGYAQm4AQfIAQzYAQPoAQGIAgGoAgO4AtDrhJMGwAIB0gIkZjQzNmY0MTQtMjY3OS00NGE0LTkwOWEtNGQ3YzQ0OTY1Mjc42AIE4AIB&lang=en-gb&sid=b9d75b447deb2624c8cfaadad9969120&sb=1&sb_lp=1&src=index&src_elem=sb&error_url=https://www.booking.com/index.en-gb.html?label=gen173nr-1DCAEoggI46AdIM1gEaGKIAQGYAQm4AQfIAQzYAQPoAQGIAgGoAgO4AtDrhJMGwAIB0gIkZjQzNmY0MTQtMjY3OS00NGE0LTkwOWEtNGQ3YzQ0OTY1Mjc42AIE4AIB;sid=b9d75b447deb2624c8cfaadad9969120;sb_price_type=total&;&ss=Hong Kong&is_ski_area=0&ssne=Hong Kong&ssne_untouched=Hong Kong&dest_id=-1353149&dest_type=city&checkin_year=2022&checkin_month=4&checkin_monthday=25&checkout_year=2022&checkout_month=4&checkout_monthday=30&group_adults=2&group_children=0&no_rooms=1&b_h4u_keep_filters=&from_sf=1"
requests.get(url)
response = requests.get(url)
response.status_code
soup = BeautifulSoup(response.content,'html.parser')
#filter all elements with tag span, class bui-card__title and itemprop as name
hotels = soup.findAll("span", {"class": "bui-card__title", "itemprop": "name"})
for hotel in hotels:
print(hotel.decode_contents().strip())
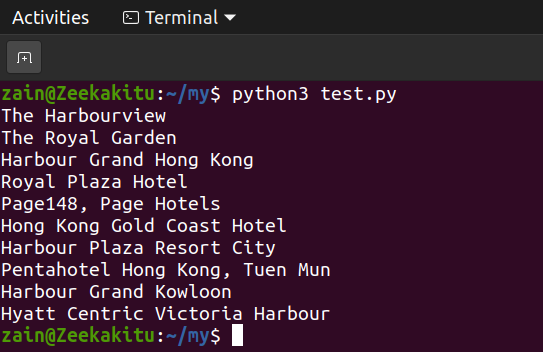
Output is following