I have a request that gets me some data that looks like this:
[{'__rowType': 'META',
'__type': 'units',
'data': [{'name': 'units.unit', 'type': 'STRING'},
{'name': 'units.classification', 'type': 'STRING'}]},
{'__rowType': 'DATA', '__type': 'units', 'data': ['A', 'Energie']},
{'__rowType': 'DATA', '__type': 'units', 'data': ['bar', ' ']},
{'__rowType': 'DATA', '__type': 'units', 'data': ['CCM', 'Volumen']},
{'__rowType': 'DATA', '__type': 'units', 'data': ['CDM', 'Volumen']}]
and would like to construct a (Pandas) DataFrame that looks like this:
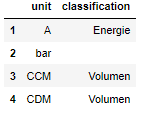
Things like pd.DataFrame(pd.json_normalize(test)['data'] are close but still throw the whole list into the column instead of making separate columns. record_path sounded right but I can't get it to work correctly either.
Any help?
CodePudding user response:
It's difficult to know how the example generalizes, but for this particular case you could use:
pd.DataFrame([d['data'] for d in test
if d.get('__rowType', None)=='DATA' and 'data' in d],
columns=['unit', 'classification']
)
NB. assuming test the input list
output:
unit classification
0 A Energie
1 bar
2 CCM Volumen
3 CDM Volumen
CodePudding user response:
Instead of just giving you the code, first I explain how you can do this by details and then I'll show you the exact steps to follow and the final code. This way you understand everything for any further situation.
When you want to create a pandas dataframe with two columns you can do this by creating a dictionary and passing it to DataFrame class:
my_data = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=my_data)
This will result in this dataframe:
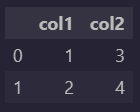
So if you want to have the dataframe you specified in your question the my_data dictionary should be like this:
my_data = {
'unit': ['A', 'bar', 'CCM', 'CDM'],
'classification': ['Energie', '', 'Volumen', 'Volumen'],
}
df = pd.DataFrame(data=my_data, )
df.index = np.arange(1, len(df) 1)
df
(You can see the df.index=... part. This is because that the index column of the desired dataframe is started at 1 in your question)
So if you want to do so you just have to extract these data from the data you provided and convert them to the exact dictionary mentioned above (my_data dictionary)
To do so you can do this:
# This will get the data values like 'bar', 'CCM' and etc from your initial data
values = [x['data'] for x in d if x['__rowType']=='DATA']
# This gets the columns names from meta data
meta = list(filter(lambda x: x['__rowType']=='META', d))[0]
columns = [x['name'].split('.')[-1] for x in meta['data']]
# This line creates the exact dictionary we need to send to DataFrame class.
my_data = {column:[v[i] for v in values] for i, column in enumerate(columns)}
So the whole code would be this:
d = YOUR_DATA
# This will get the data values like 'bar', 'CCM' and etc
values = [x['data'] for x in d if x['__rowType']=='DATA']
# This gets the columns names from meta data
meta = list(filter(lambda x: x['__rowType']=='META', d))[0]
columns = [x['name'].split('.')[-1] for x in meta['data']]
# This line creates the exact dictionary we need to send to DataFrame class.
my_data = {column:[v[i] for v in values] for i, column in enumerate(columns)}
df = pd.DataFrame(data=my_data, )
df.index = np.arange(1, len(df) 1)
df #or print(df)
Note: Of course you can do all of this in one complex line of code but to avoid confusion I decided to do this in couple of lines of code