First look at the pure CPU mobilenet - SSD FP32 performance model of reasoning, my hand is a 4 core i5 7440 hq 4 thread mobile processors,
First batch size=1, where each reasoning only input image,
The inference request (nireq)=1, namely at the same time only a reasoning request
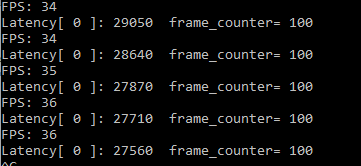
For every 100 frame reasoning computation time required to print a order time reasoning Latency (us), as well as the overall reasoning performance throughput (FPS)
The Latency is about 28 ms, Throughtput is 36 FPS
Inference request (nireq)=4, namely setting CPU_THROUGHPUT_STREAMS=CPU_THROUGHPUT_AUTO, concurrency is 4 openvino suggest, concurrent requests four reasoning
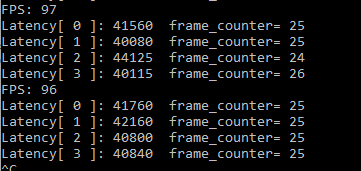
The Latency is about 40 ms, Throughtput for 96 FPS
Can see concurrent 4-way reasoning, single-channel reasoning will be long, but the total throughput greatly ascend, is to make better use of the hardware, at the same time each way of reasoning process frames is roughly same, about 25 frame, the consistency is good, basically can guarantee first reasoning first end
See next batch size=3, inference request (nireq)=4, where each inference processing three images, 4-way reasoning concurrent
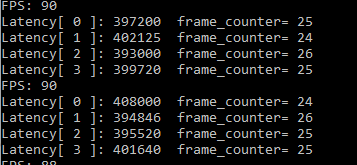
A single frame, with the increase of single reasoning data Latency is slightly larger (code wrong here, and the real figure should be divided by 9), FPS also fell slightly, increase the amount of a single data instead of having a negative effect on performance, description of hardware processing capacity is the way it is, no amount of data can only increase program scheduling overhead repeatedly, can not go further on the performance,
The final measure of pure CPU mobilenet - SSD FP16 model performance, found that performance and FP32 basic consistent, it also confirms openvino's official website, when the CPU of reasoning, if the loading FP16 model, when loading the FP16 into FP32
Simple summarize, OpenVINO CPU inference
Reasoning concurrency determines the size of the Lantency, if need to quickly get reasoning as a result, the best concurrency is 1, i.e. let openvino all hardware focus for a single reason, if you want to obtain high throughput, you need to increase concurrency,
CPU reasoning "CPU_BIND_THREAD" basic "distasteful, because does not specify which bind to the physical kernel, and so may have a negative impact, and other code is tied to the same physical cores)
When the CPU reasoning load FP32/FP16 model, reasoning performance is the same as
CPU reasoning very easily affected by the background program, such as the background of virus scan, or Windows update thread, performance could fall by more than 10%
CPU limit mining reasoning performance when it is easy to cause the CPU overheating lead to slow, at this time can hear the fans crazy ring, at this time the performance will fall sharply