The first is FP32 model
When the Batch size=1
The inference request (nireq)=1, namely at the same time only a reasoning request
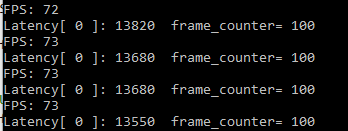
Latency=13.6 ms, Throughtput=73 FPS, performance is good, more than 2 times the CPU
Inference request (nireq)=4, namely setting GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO, openvino suggested number of stream number is 2, and the corresponding number of ireq concurrency is 4, concurrent requests four reasoning
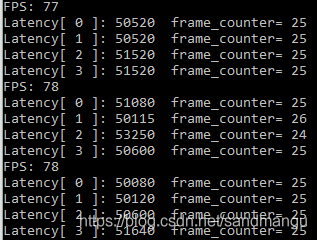
This is a bit awkward, Throughtput=78 FPS, ascension is not big, the corresponding reasoning is CPU 96 FPS, at that time than the CPU performance, then every road reasoning consistency is good, every road work consistent
See next batch size=3, inference request (nireq)=4, where each inference processing three images, 4-way reasoning concurrent
the condition of the
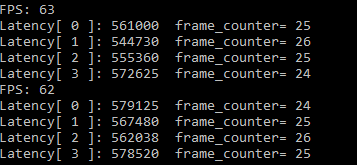
63 FPS, integrated graphics limited resources, once the amount of data is beyond the scope of hardware capacity performance will be discounted
The next is FP16 model
When the Batch size=1
The inference request (nireq)=1, namely at the same time only a reasoning request
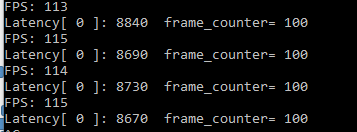
Latency: 9, ms Throughtput: 113 FPS, this figure compared with best CPU FP32
Inference request (nireq)=4, namely setting GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO, openvino suggested number of stream number is 2, and the corresponding number of ireq concurrency is 4, concurrent requests four reasoning
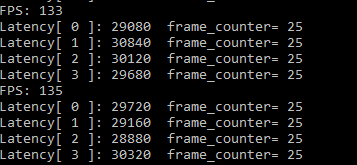
133 FPS, it seems the GPU, indeed, relative to the CPU is more suitable for reasoning, relative to the FP32 model at the same time, because FP16 demand model of memory bandwidth is reduced by half, so performance is greatly ascend,
Or go to a batch size=3, inference request (nireq)=4, where each inference processing three images, 4-way reasoning concurrent
the condition of the
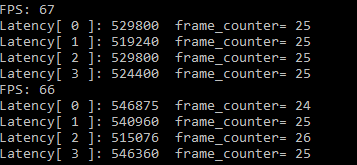
Seem to be limited hardware resources, after more than one data processing capacity will drop sharply,
GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO front are used to test, and finally look at the manual setting GPU_THROUGHPUT_STREAMS=1, namely nstream=1, nireq=2, look at the performance would halve
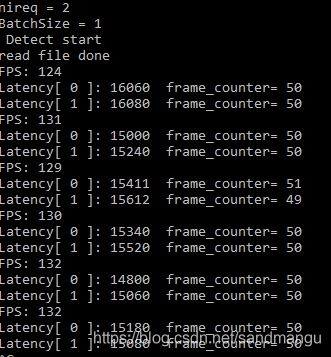
The FPS is almost like GPU_THROUGHPUT_AUTO, less than 2% of the decline, former two-way reasoning seems to have accounted for the GPU, the vast majority of resources GPU_THROUGHPUT_AUTO nireq extra 2 road again just to get some meat from the mosquito legs,
Simple to summarize, the GPU OpenVINO reasoning
For GPU reasoning FP16 performance well within FP32, basic can double
Batch size must be set to 1, because the GPU resource limitations more than CPU, so be sure to carefully, eat much food less
Reasoning concurrency, not necessarily to set, according to the suggested values of GPU_THROUGHPUT_AUTO concurrency slightly less also can obtain good performance, also can give other system applied to retain more of the resource scheduling
GPU frequency reduction reasoning is not easy to cause the CPU overheating caused by performance degradation, but also wasn't affected by the Windows of the daemon, as long as have enough CPU resources to feed the GPU data, processing speed will be relatively stable
GPU reasoning performance will be caused by other graphics program using GPU performance degradation, such as reasoning and invoke the OpenCV imshow () to cause a decline in speed of reasoning