Mobilenet - SSD, for example, the paper with a performance data comparison
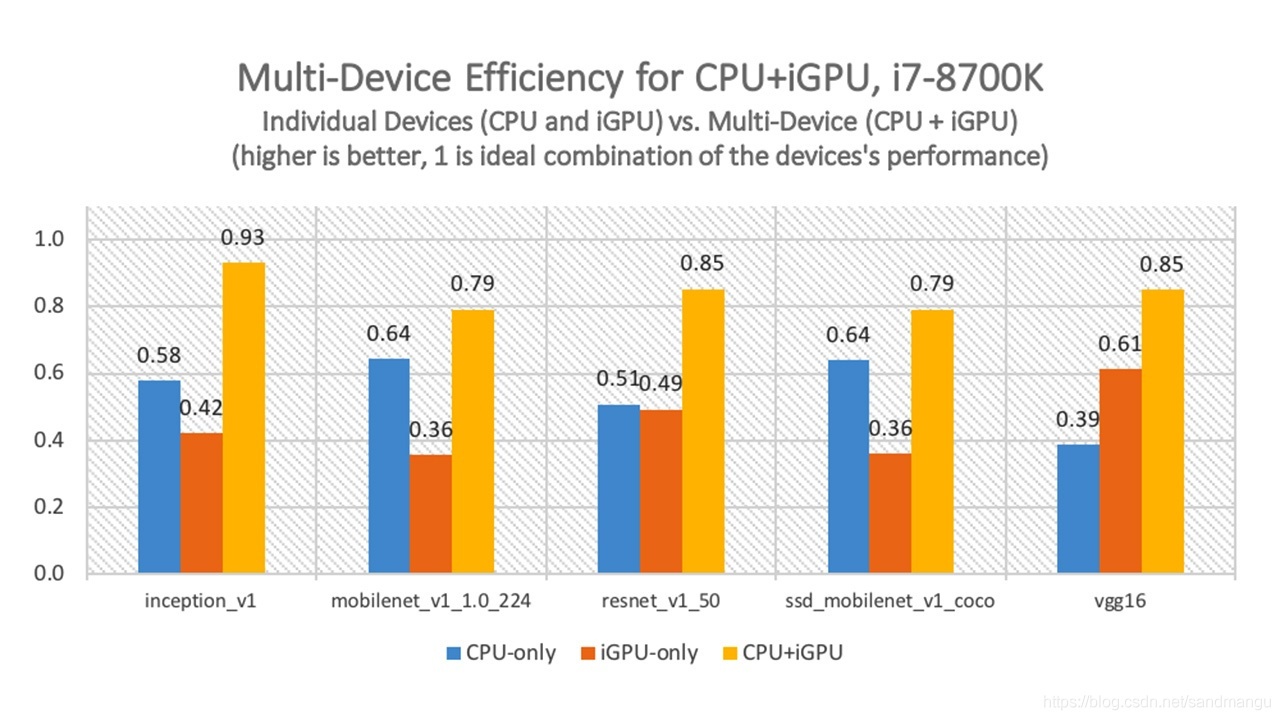
CPU/GPU together after reasoning performance relative to use reasoning, CPU performance is improved to 0.79/0.64=1.234 is increased by about 23.4%
Below we to measured the
So-called hybrid model, the actual is in step 7, called ie. When LoadNetwork device_name preach in parameters for MULTI: CPU, GPU, such LoadNetwork will reduce the model data loaded into the CPU at the same time, the GPU or other specified in the hardware,
//-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 7. Loading the model to the device -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
Next_step ();
STD: : map
CONFIG_VALUE (NO)}};
StartTime=Time: : now ();
ExecutableNetwork exeNetwork=ie. LoadNetwork (cnnNetwork, device_name, config);
Duration_ms=float_to_string (get_total_ms_time ());
Slog: : info & lt; <"The Load network took" & lt;
The statistics - & gt; AddParameters (StatisticsReport: : Category: : EXECUTION_RESULTS,
{
"{" load network time (ms), duration_ms}
});
First is FP32 model, when the Batch size=1
Benchmark_app set CPU_THROUGHPUT_STREAMS=CPU_THROUGHPUT_AUTO, GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO, get openvino advice on the number of CPU nstream is 4, GPU nstream number is 2, below the corresponding number of ireq concurrency of 8, the concurrent requests eight reasoning
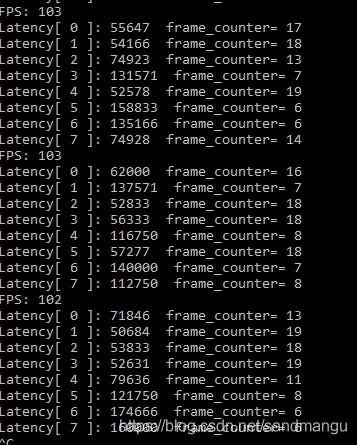
FPS is 102, relative to the CPU 97 FPS, performance improvement is not large, at the same time as you can see statistics 8-way infer request latency time is obvious different, there are 4 road is slow, there are 4 way faster, speed is controlled 1 times the basic difference, should be the speed of the CPU and GPU reasoning; Also can be seen at the same time, eight infer the time of the request reasoning is also dynamic change, not a infer request handle is fixed corresponding CPU reasoning, a handle is fixed corresponding GPU reasoning,
Next is FP16 model, when the Batch size=1
Benchmark_app set CPU_THROUGHPUT_STREAMS=CPU_THROUGHPUT_AUTO, GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO, get openvino advice on the number of CPU nstream is 4, GPU nstream number is 2, below the corresponding number of ireq concurrency of 8, the concurrent requests eight reasoning
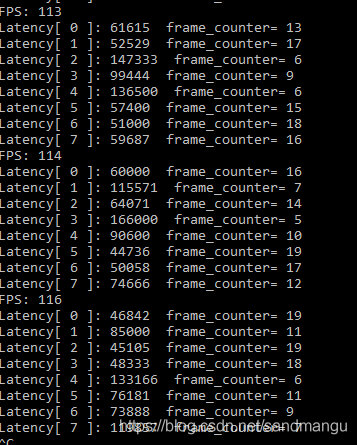
114 FPS, better than FP32 model reasoning, should be the GPU can save a part of memory bandwidth costs lead to performance improvement, but 133 FPS and pure GPU FP16 model reasoning still far worse,
In order to find the reason, offering a free big bombshell Intel Graphics Performance Analyzers, this tool can see real-time CPU, GPU in all kinds of resource usage, first take a look at the default CPU_THROUGHPUT_STREAMS=CPU_THROUGHPUT_AUTO, GPU_THROUGHPUT_STREAMS=GPU_THROUGHPUT_AUTO mode, the CPU here: 4 GPU: concurrent 4 refers to the CPU has 4 road, concurrent GPU with 4 road, a total of eight road
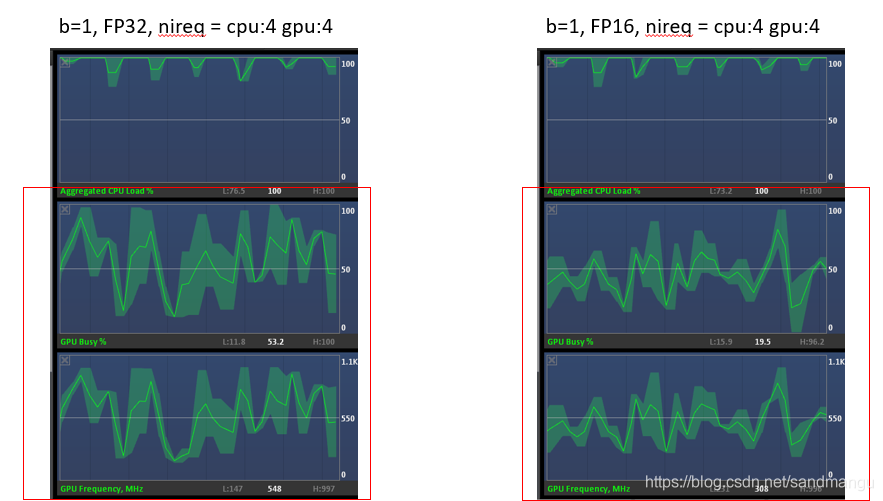
Can see the reasoning has been consumed 100% CPU, but the frequency of the GPU is around 500 hz all, occupancy rate is about 50% at the same time, the main reasoning for calculation is on this side of the CPU, GPU just took time to do some work, don't know is not enough memory bandwidth or no CPU resources to feed the GPU data, lead to basic half an idle state, the so-called performance improvement from 97 FPS to Multi CPU FP32 FP32 102 FPS, namely the GPU to help do a little work; And Multi FP16 114 FPS is higher than that of Multi FP32 102 FPS, that is because gpus in FP16 calculation is more efficient,
Try again cut down the number of concurrent, reasoning, from 1 road to two-way reasoning concurrent concurrent 4-way reasoning, GPA output below
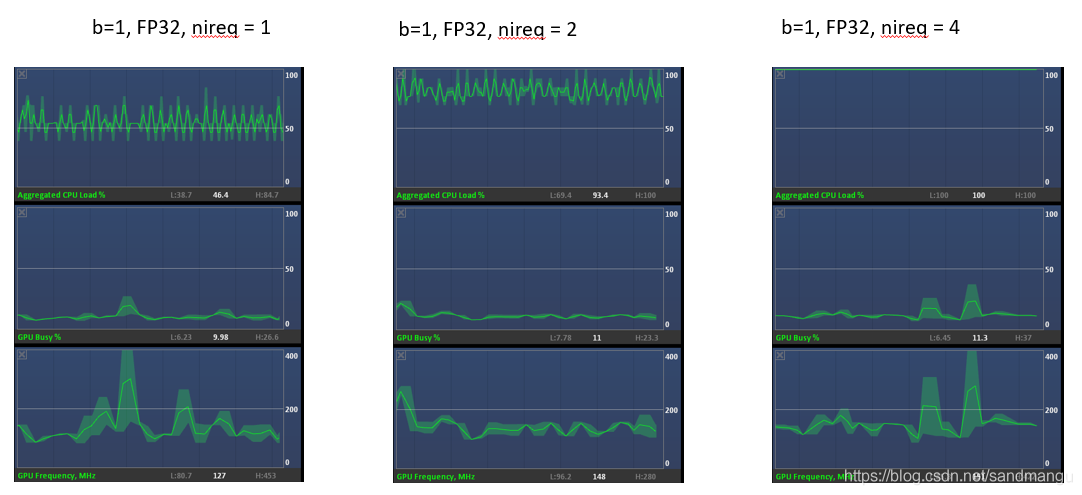
Very interesting, can see that with the increase of concurrency, CPU utilization rate is increased, the GPU has been idle
To increase the number of concurrent
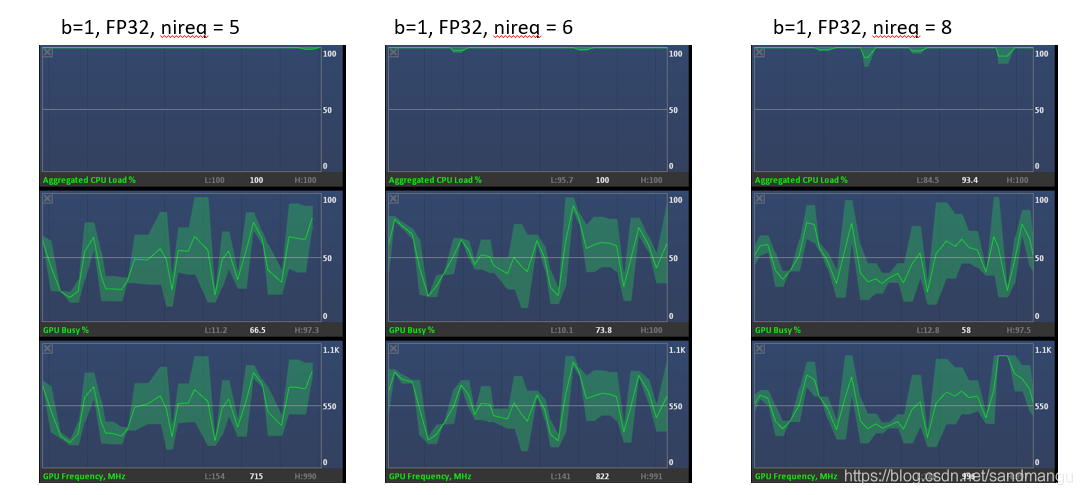
When concurrency from 5, GPU started to participate in the reasoning in the calculation,
So can the basic thought, the use of MULTI: CPU, GPU parameters, and all use XXX_THROUGHPUT_AUTO parameters, inference engine scheduling logic is the CPU resources first run full (concurrent & lt;=4 road) to start using the GPU resources (concurrent & gt; 4)
In practical use of it is a very troublesome thing, we can't know the current create multiple infer handle to request which is corresponding to the CPU, which is corresponding to the GPU, completely is IE engine control
For (int I=0; I & lt; Nireq; I++)
{
InferRequest. [I]=exeNetwork CreateInferRequest ();
}
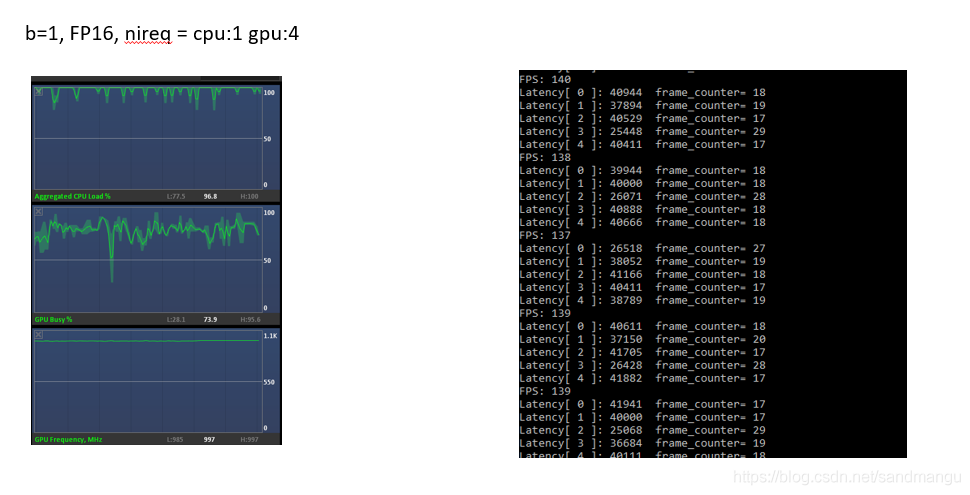
So the only way to reduce the CPU infer the amount of the request, such as by manually set the number of cpu_nstream, try the CPU nireq=1, the gpu nireq=4, FP16 model
//-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 6. Setting device configuration -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
Ie. SetConfig ({{CONFIG_KEY (CPU_BIND_THREAD), and "NO"}}, "CPU");
std::cout <"CPU_BIND_THREAD:" & lt;
//for CPU execution, more throughput - oriented execution via streams
//ie. SetConfig ({{CONFIG_KEY (CPU_THROUGHPUT_STREAMS), "CPU_THROUGHPUT_AUTO"}}, "CPU");
Ie. SetConfig ({{CONFIG_KEY (CPU_THROUGHPUT_STREAMS), STD: : to_string (1)}}, "CPU");
Cpu_nstreams=STD: : stoi (ie. GetConfig (" CPU ", CONFIG_KEY (CPU_THROUGHPUT_STREAMS). As
std::cout <"CPU_THROUGHPUT_AUTO: Number of CPU streams=" & lt;
//for GPU inference
//ie. SetConfig ({{CONFIG_KEY (GPU_THROUGHPUT_STREAMS), "GPU_THROUGHPUT_AUTO"}}, "GPU");
Ie. SetConfig ({{CONFIG_KEY (GPU_THROUGHPUT_STREAMS), "4"}}, "GPU");
Gpu_nstreams=STD: : stoi (ie. GetConfig (" GPU, "CONFIG_KEY (GPU_THROUGHPUT_STREAMS). As
std::cout <"GPU_THROUGHPUT_AUTO: Number of GPU streams=" & lt;
Ie. SetConfig ({{CLDNN_CONFIG_KEY (PLUGIN_THROTTLE), "1"}}, "GPU");
std::cout <"CLDNN_CONFIG_KEY (PLUGIN_THROTTLE), 1" & lt;
GPA output
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull