The following field the
Building environment
Install docker for Windows, step by step according to the Windows installation part of the connection to Install DL Workbench from docker Hub * * OS on Windows
Install DeepLearning Workbench
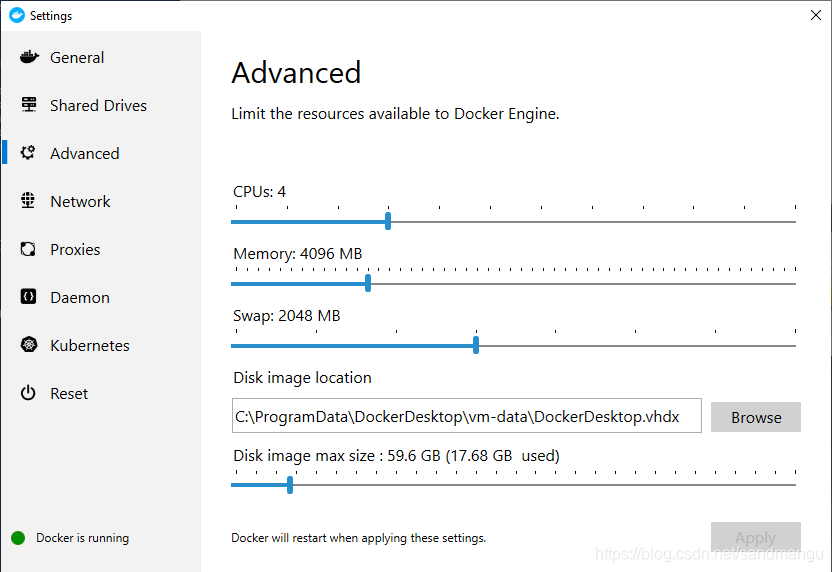
Screen the docker icon on the right mouse button and the bottom right hand corner, enter Setting, set memory a bit bigger, otherwise wait conversion could cause crash because of memory, set the docker will automatically restart after the completion of the
Start powershell, run the following command pull the docker mirror image to the local
Docker pull openvino/workbench: latest
Run the following command to start the workbench container
Docker run - p 127.0.0.1: \ 5665-5665
- the name workbench \
- ring \
- v/dev/bus/usb:/dev/bus/usb \
- v/dev/dri:/dev/dri \
- e PROXY_HOST_ADDRESS=0.0.0.0 \
PORT=5665 - e \
- it openvino/workbench: latest
See the powershell hua hua run would be better to print out a bunch of words
Later you want to run, run directly in the powershell
Docker start - a workbench
Then open the Chrome browser (do not use edge), open the address 127.0.0.1:5665, if the following web page can use the
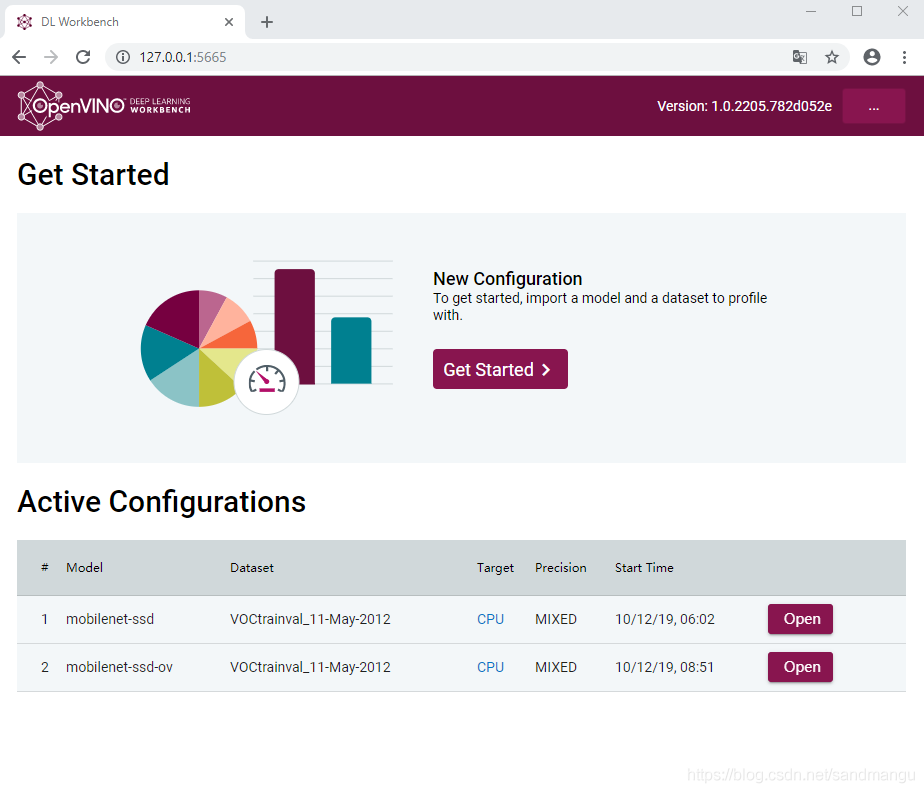
The Workbench can help you to see the topology model file, test the performance of reasoning and precision, and do FP32/FP16/INT8 conversion,
Specific model import tutorial can refer to Intel's website Work with Models and the Sample Datasets
Transition Mobilenet - SSD model is very simple, according to the official website tutorial
Import the downloaded mobilenet - SSD caffe model
Import a data set for correction, must use ImageNet or Pascal VOC conversion INT8 model format of the data set, here I use VOC's official data set
First verify mobilenet - SSD official model accuracy,
When do INT8 transformation, the transformation of the need to allow precision loss and use the percentage of the data set
Waiting for conversion completed
Download the converted INT8 model to the local
I validation of the model precision is set to
Convert good web page shows the following
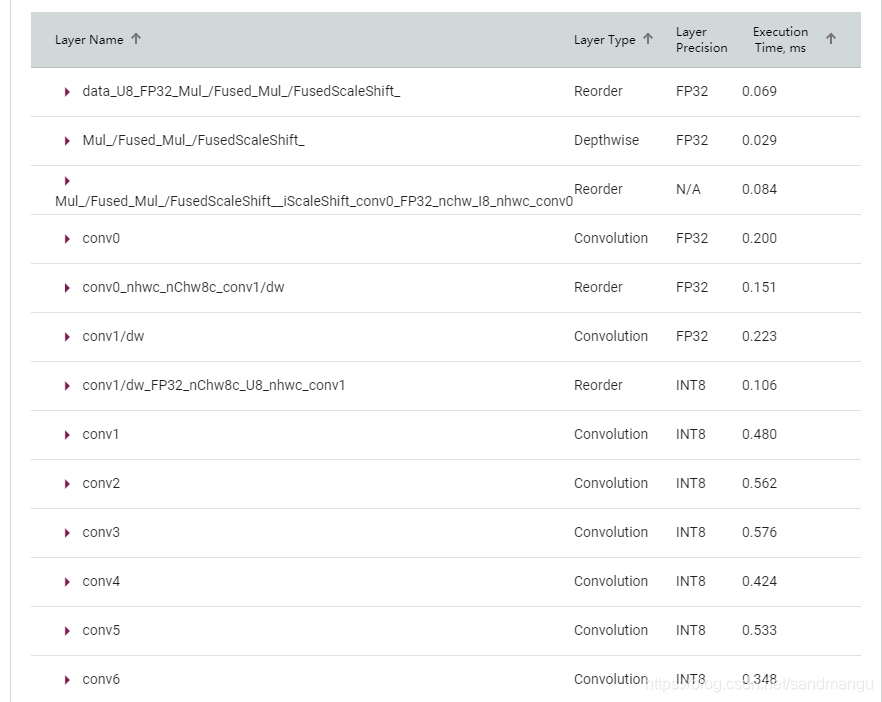
INT8 model of the data type of each layer can be seen directly, not all layers are transformed into INT8
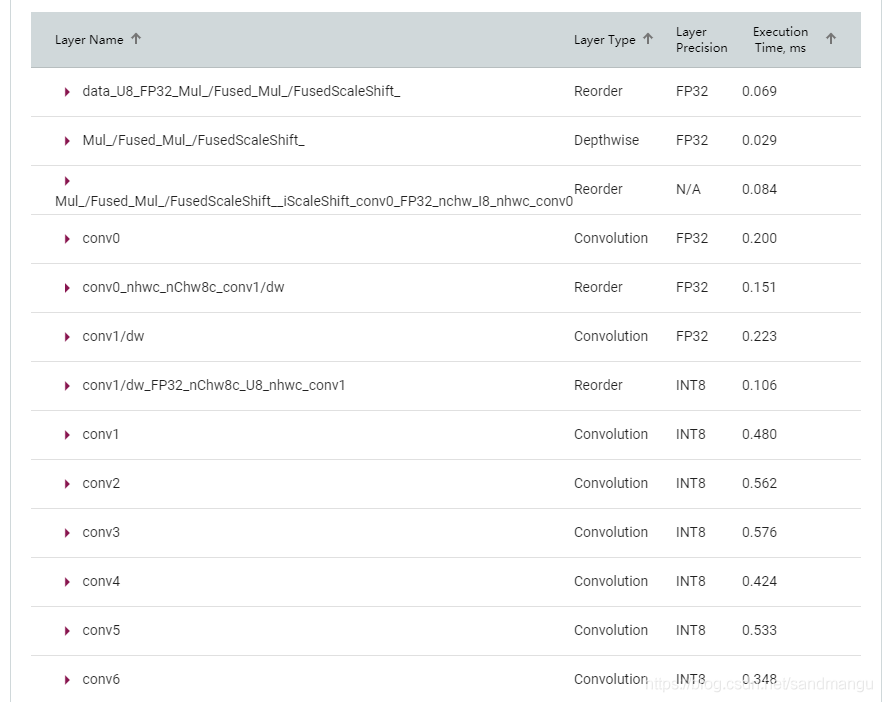
Try the model into the benchmark program in front of the
CPU Batchsize=1, 48 FPS nireq=1 Throughput:
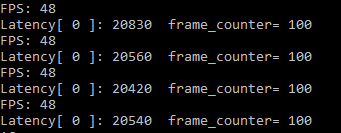
CPU Batchsize=1, nireq=4 Throughput: 133 FPS
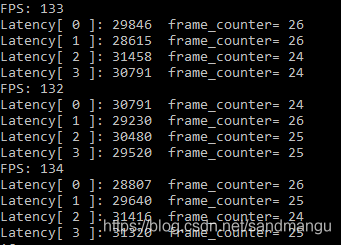
Performance of INT8 model is loaded into the GPU, reasoning and GPU FP32 consistent, visible GPU internally converted INT8 model into FP32
Measured again under MULTI: CPU, GPU INT8 Batchsize=1, nireq=8 (CPU_THROUGHPUT_AUTO/GPU_THROUGHPUT_AUTO), Throughput: 150 FPS
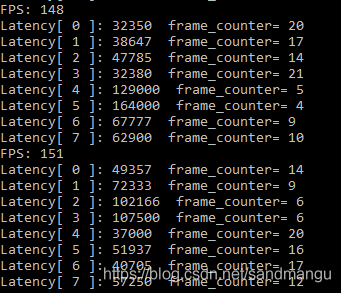
The performance with MULTI: CPU, GPU FP16 best similar data, though probably because the CPU is INT8 is fast, but the GPU FP32 calculation instead of doing, dragging the hind legs,
Simple summarize, OpenVINO CPU INT8 inference
CPU performance and GPU INT8 reasoning FP16 similar performance, relative to the CPU FP32 has more than 30% of the performance improvement, if CPU reasoning inference model can be converted into INT8 mode, or use INT8 model
OpenVINO INT8 model transformation is just as far as possible in the case of ensure the accuracy of the set to identify certain layer into INT8, does not exist in the process of converting INT8 to use training data sets to improve the precision of process, so the model conversion efficiency is not high, turn out the model is a mixture of FP32/INT8, not pure INT8 model
Currently 2019 r3 release OpenVINO INT8 model transformation is just for some public model is more friendly, open source Layer to support those who have the Custom Custom Layer model transformation is very troublesome, effect is not good
INT8 model for the GPU is FP32 model, so the GPU using INT8 model efficiency is not high, try not to give the GPU load INT8 model
Finally, the above results are mobilenet - SSD to test, according to data INT8 multi mode and FP16 multi mode performance is close to, but there's no analysis where cannot ascend the cause of the performance, don't know at this point in memory bandwidth bottleneck or on the amount of calculation, the model for other reasons, may be the result is not the same; For other hardware platform at the same time, the possible outcome is different also, some laptop platform Intel integrated graphics performance more, most of the desktop CPU frequency and auditing is more, so it is possible that test results is different also, but just do reasoning in terms of computing, common CPU and integrated graphics is also can play a significant number of real-time reasoning computing needs,